


概述
容器技术的大多数问题,最终都可以映射到 Linux 操作系统的相应模块上,这篇文章就是对容器底层的操作系统内核知识的总结。文章内容主要来自于极客时间的《容器实战高手课》这个专栏。按照作者的说法,只有能真正掌握底层那些不变的技术,可以更加从容地去接受技术的瞬息万变。
容器技术原理
容器技术的本质就是Linux的Namespace和Cgroup技术的叠加。Namespace用于资源隔离,Cgroup则用于资源限制。
Namespace
Namespace是一种隔离机制,主要目的是隔离运行在同一个宿主机上的不同进程,让不同的Namespace下的进程之间不能访问彼此的资源。
Linux内核提供了多种Namespace,不同的Namespace用于隔离不同的资源。比如PID Namespace用于隔离进程,让不同Namespace下的进程无法看到对方;而Network Namespace则负责网络环境的隔离,每个Network Namespace拥有自己独立的lo和eth0网卡,等等。
Linux提供的Namespace主要有以下几种:
PID Namespace
允许进程拥有独立的进程ID空间。不同的 PID Namespace 中的进程可以有相同的 PID,例如,容器内的进程可以从 1 开始编号,而不会与宿主机上的进程冲突。并且容器内也看不到其他容器,或者外部宿主机上的其他进程。
Network Namespace
为容器提供独立的网络堆栈,包括网络接口、路由表、IP 地址和端口等。每个 Network Namespace 可以有自己的网络配置,实现容器间的网络隔离。
Mount Namespace
允许各个容器有独立的文件系统视图。每个 Mount Namespace 可以拥有自己的挂载点,容器可以在其中创建、删除和修改文件系统的挂载。容器中的根文件系统,其实就是我们做的镜像,可以完全独立于宿主机的根文件系统,就是依赖的Mount Namespace实现。
UTS Namespace
允许容器拥有独立的主机名和域名。通过 UTS Namespace,容器可以设置自己的主机名,而不会影响宿主机或其他容器的主机名。
IPC Namespace
隔离进程间通信资源,包括 System V IPC 和 POSIX IPC。每个 IPC Namespace 拥有自己的消息队列、共享内存和信号量,进程在不同的 IPC Namespace 中无法相互通信,也用于保证进程的隔离。
User Namespace
允许容器内的用户与宿主机的用户进行隔离。容器内的用户可以有不同的用户和组 ID,提供了更好的安全性,限制了容器内进程的权限。
CGroup Namespace
隔离 cgroup 的视图,使得进程在不同的 CGroup Namespace 中可以拥有不同的资源限制和监控信息。
通过以上这些Namespace,容器才得以从宿主机中隔离出来,让它看起来像一个虚拟机。通过lsns命令可以查看到当前机器上有哪些Namespace,比如:
# lsns -t pid
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 126 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 17
4026532311 pid 1 1603 systemd-coredump mysqld --default-authentication-plugin=caching_sha2_password --character-set-server=utf8mb4 --colla
4026532379 pid 2 1635 root sh -c java ${JVM_OPTS} org.springframework.boot.loader.launch.JarLauncher ${0} ${@} --spring.r2dbc.
4026532447 pid 15 1662 root /package/admin/s6/command/s6-svscan -d4 -- /run/serviceCgroup
Cgroups(Control Groups),是Linux内核提供的一种功能,它允许将进程组织到一个组中,并对该组进行资源管理和限制。Cgroups可以对指定的进程做各种计算机资源的限制,比如限制CPU的使用率,内存使用量,IO设备的流量等等。
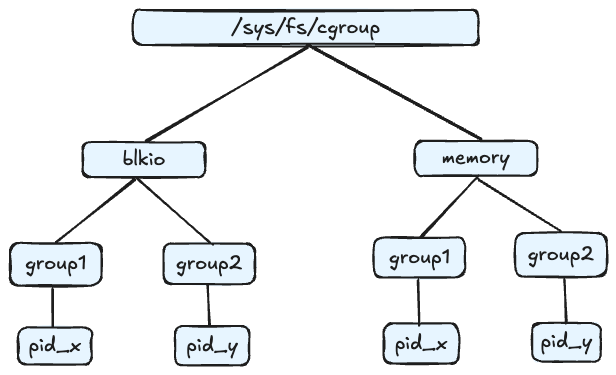
Cgroups 通过不同的子系统限制了不同的资源,每个子系统限制一种资源。每个子系统限制资源的方式都是类似的,就是把相关的一组进程分配到一个控制组里,然后通过树结构进行管理,每个控制组都设有自己的资源控制参数。
常用的Cgroup子系统:
cpu子系统,用来限制一个控制组(一组进程),可使用的最多cpu时间
memory子系统,用来限制一个控制组最大的内存用量
blkio子系统,用于控制和监控块设备I/O的使用
net_cls子系统,用于给网络数据包标记,便于进行流量控制和QoS(Quality of Service)管理
pids子系统,用来限制一个控制组内最多能运行多少个进程
cpuset子系统,用来限制一个控制组内的进程可以在哪几个物理cpu上运行
devices子系统,用于限制一个控制组对设备的访问权限
Cgroup通过文件目录的形式对外提供操作接口,位于目录/sys/fs/cgroup/。每种子系统都会在这个目录下面拥有自己的目录:
# ls /sys/fs/cgroup
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb ioasids memory net_cls net_cls,net_prio net_prio perf_event pids rdma systemd同样地,每个控制组,需要控制的资源,也需要在子系统目录下创建自己的目录,比如docker容器:
# ls /sys/fs/cgroup/memory/system.slice/
docker-c5a9ff78d9c1fedd52511e18fdbd26357250719fa0d128349547a50fad7c5de9.scope每种Cgroup的子系统会通过不同的参数进行资源的控制。比如memory子系统通过写入到文件memory.limit_in_bytes实现控制组对内存的限制。其他子系统也有自己的控制方式。类似地,也都是通过写入到对应文件中来实现。
Cgroup有v1和v2两个版本。v1版本各个子系统(如 CPU、内存、I/O 等)相对独立,很灵活但是彼此之间的协调性较差,比如memory和blkio之间就无法协作。但是在今天大部分环境中仍然还是v1版本,Linux内核的默认Cgroup版本也是v1。v2版本解决了v1版本多个子系统协作的问题,并且更容易使用,但是并不完全向后兼容v1,所以如果想从v1迁移到v2,需要一些成本。
容器进程
init进程
init进程,也叫1号进程(pid为1的进程),是系统启动时创建的第一个用户空间进程。在Linux系统启动时,内核在完成操作系统各种初始化之后,就会从几个缺省路径中尝试执行init进程,从而从内核态切换到用户态。目前主流的Linux发行版,都会把Systemd作为init进程启动,init进程最基本的功能就是创建出Linux系统中其他的进程,并管理这些进程。
而一旦容器启动,建立了自己的Namespace,这个Namespace里的第一个进程就是这个容器的init进程,它需要承担起容器中其他进程的创建和管理义务。容器也是靠init进程来hold住整个容器保持Running的,当init进程退出,容器也会随着退出。
信号
信号是Linux中的一种通知机制,使得进程能够接收来自内核或其他进程的事件通知。Linux中的信号有几十种,从1开始编号。可以通过命令查看:
# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX比如我们执行Ctrl+C命令,对应的进程就会收到SIGINT信号而退出。如果进程的内存访问出错了,那么进程就会收到内核的SIGSEGV信号。
在Linux的Shell里,可以通过kill <pid>命令向进程发送信号,缺省状态下kill命令会向进程发送15号也就是SIGTERM信号,如果要指定发送9号SIGKILL信号,则使用kill -9 <pid>即可。
进程在收到信号时,会有一个缺省的处理行为,一般是退出、暂停、或者忽略。其中SIGKILL和SIGSTOP这两个信号比较特殊,它们是无法被被捕获的,只能执行缺省行为,也就是退出。这种设计主要是为了让超级用户拥有可以删除任意进程的权限。而其他信号在被进程收到时,可以被进程捕获,并由进程自己决定是忽略还是要执行一些代码逻辑。进程可以通过signal()这个系统调用注册自己关注信号的handler,那么在收到对应信号时,就可以捕获到并执行handler。那么由于SIGKILL和SIGSTOP信号无法被捕获,所以这两个信号也是无法注册handler的。
而init进程较为特殊,在Linux中,init进程在同一个Namespace下收到的SIGKILL和SIGSTOP信号会被忽略。也就是说,如果我们尝试在容器中,通过kill -9 1的方式杀掉init进程是不行的,SIGKILL信号会被忽略掉。
Note:
内核在决定把信号发给PID Namespace下的1号进程时,会调用sig_task_ignored()这个函数来判断是否需要忽略该信号。该函数主要做了三个判断:
1. 是否信号来自于同一个Namespace;
2. 进程是否没有对该信号注册handler,使用缺省行为;
3. 进程是否被打上了SIGNAL_UNKILLABLE的标签。init进程是会被打上该标签的。
那么在同一个PID Namespace下使用
kill -9 1时,第一个条件满足,第二个条件由于SIGKILL和SIGSTOP信号无法注册handler,所以也满足,第三个条件init进程天然满足,三个条件都满足,则init进程收到的SIGKILL或SIGSTOP信号会被忽略。
那么根据上述说明,init进程收到的即使不是SIGKILL或SIGSTOP信号,其他信号只要没有注册handler,也会被忽略。
对于Golang实现的init程序,很多信号都是默认被注册了handler的,所以在容器中,使用kill 1命令向init进程发送SIGTERM命令,是可以关掉进程的;而对于C实现的init程序,默认是不会对任何信号注册handler,所以C程序除非主动注册handler,否则任何信号都无法停止init进程。
僵尸进程
僵尸进程是指已经完成执行但仍然存在于进程表中的进程。它是进程生命周期的一部分,当一个子进程结束时,它会向其父进程发送一个信号,通知其结束。父进程需要调用 wait() 或 waitpid() 函数来读取子进程的退出状态并清理其进程表项。如果父进程没有及时处理这个信息,子进程就会变成僵尸进程。通过ps aux命令查看,僵尸进程的名字后会带有<defunct>标记,STAT字段为Z。
Note:
在进程调用
do_exit()退出时,会有两个状态:一个是EXIT_DEAD,一个是EXIT_ZOMBIE状态。
EXIT_DEAD:进程真正退出的状态。
EXIT_ZOMBIE:就是进程在EXIT_DEAD之前的一个状态。该状态时,进程的资源基本已被清理,也不会再响应信号,但是还占用着进程号,需要父进程调用
wait()或者waitpid()系统调用来清理子进程的系统资源,比如进程号。由于父进程没有调用
wait()或者waitpid()系统调用从而导致子进程执行完成后一直停在EXIT_ZOMBIE状态的进程,就是僵尸进程。子进程在结束时,会向父进程发送SIGCHILD信号,所以父进程也可以通过注册SIGCHILD的处理函数异步回收资源。
由于僵尸进程会占用进程号,而我们的容器中一般会使用Cgroup的pids子系统来限制容器内的进程总数,那么大量僵尸进程就会占用正常进程的进程号,甚至导致正常进程无法创建。
避免僵尸进程的出现,只能是由容器内的init进程通过wait()或者waitpid()来及时回收掉子进程的系统资源。社区提供了tini这个工具专门用于作为容器内的init进程运行,可以及时清理掉僵尸进程,并且还能在收到信号时,向子进程传递信号。
如何优雅终止
Containerd在停止容器时,会向容器的init进程发送一个SIGTERM信号,SIGTERM信号可以被init进程捕获,从而做一些清理动作,实现优雅退出(graceful shutdown)。但是init进程在退出时,会向PID Namespace中的其他子进程发送SIGKILL信号,而SIGKILL信号是无法被捕获的,子进程会立刻退出,无法做到graceful shutdown了。
那么如何让容器里除了init进程外的其他进程也实现优雅退出呢?可以让init进程来转发SIGATERM信号。即init进程在收到Containerd的SIGTERM信号后,在自己退出之前,发送SIGTERM信号给所有的子进程,这样子进程就也能够捕获到SIGTERM,从而进行自己的清理动作了。实际上tini也是这样实现的,它会在收到除了SIGCHLD信号以外的其他信号时,将信号全部转发给自己管理的所有子进程。
CPU类型
下面这个图表示进程消耗CPU的各个阶段,上半部分是用户态,下半部分是内核态,我们从左到右进行分析。
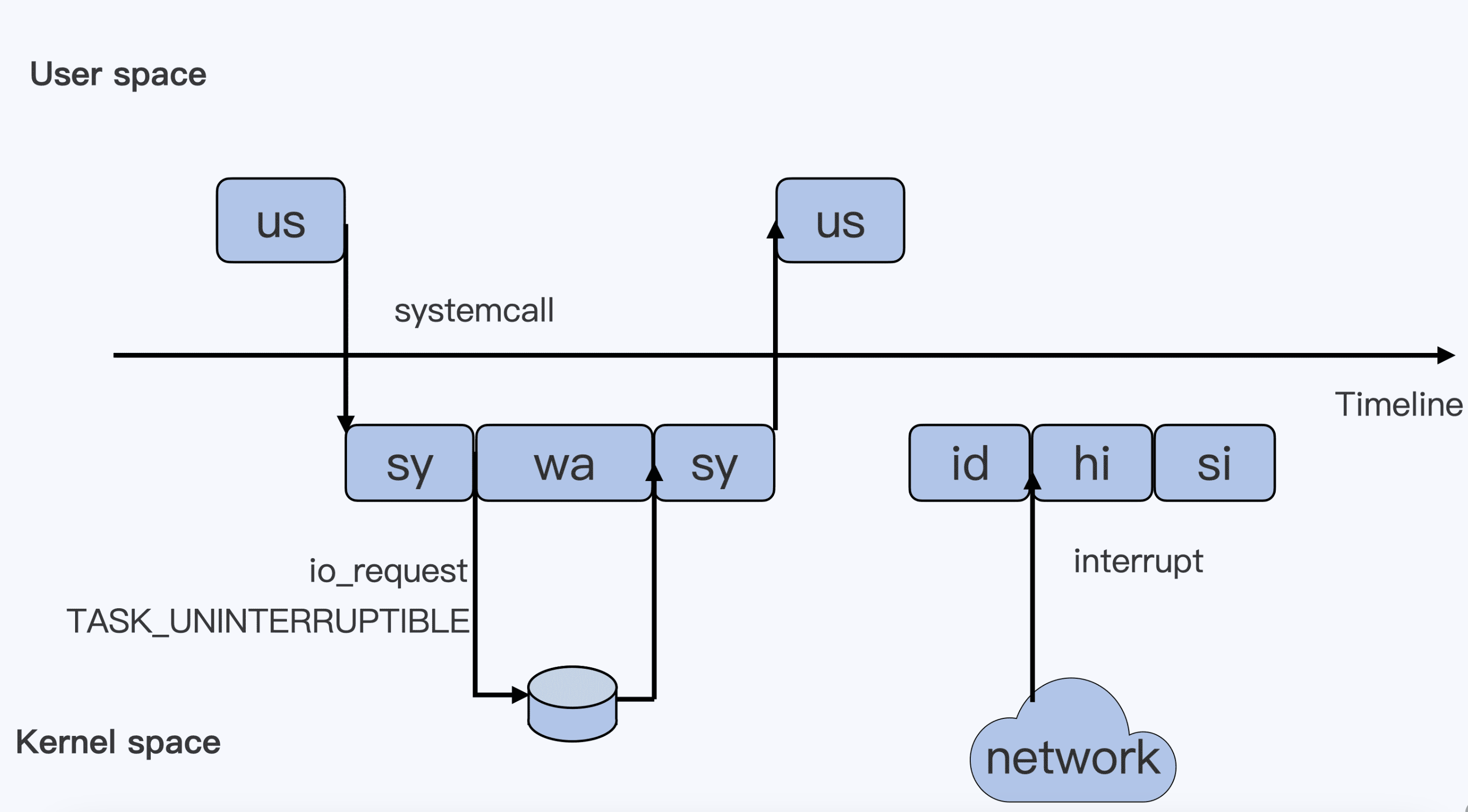
当一个用户进程开始运行,就对应的us阶段,代表CPU的User Usage,也就是执行用户进程除了系统调用之外的普通代码。
当用户进程开始执行系统调用,那么就会从用户态切换到内核态,进入到sy的阶段,s代表System。
当内核态系统调用向硬件层发起请求并等待返回时,该进程会被标记为TASK_UNINTERRUPTIBLE(如上所述,是进程处于睡眠态的不可中断状态)。这个阶段就是wa,也就是iowait的意思。
接着硬件层返回数据,则此时回到sy阶段。
接下里再从内核态切回用户态,回到us阶段。
如果用户进程什么事都不做,处于休眠状态时,系统会进入id阶段,也就是空闲idle的意思。
如果用户进程有监听套接字,那么当网卡收到网络数据包时,网卡会向监听的进程发出一个中断,那么CPU会响应这个中断,进入hi阶段,h代表hardware,即处理硬中断过程。
由于硬中断处理的工作可能会比较耗时,则这些耗时较长的工作是由软中断,即si来完成的。hi和si都不会算入进程的CPU时间。
除了这些以外,还有两种CPU使用类型。ni,代表nice值(1-19),代表优先级比较低的进程运行时所占用的CPU;si,代表steal,用于虚拟机里,表示多少时间是被同一个宿主机上的其他虚拟机抢走的CPU时间。
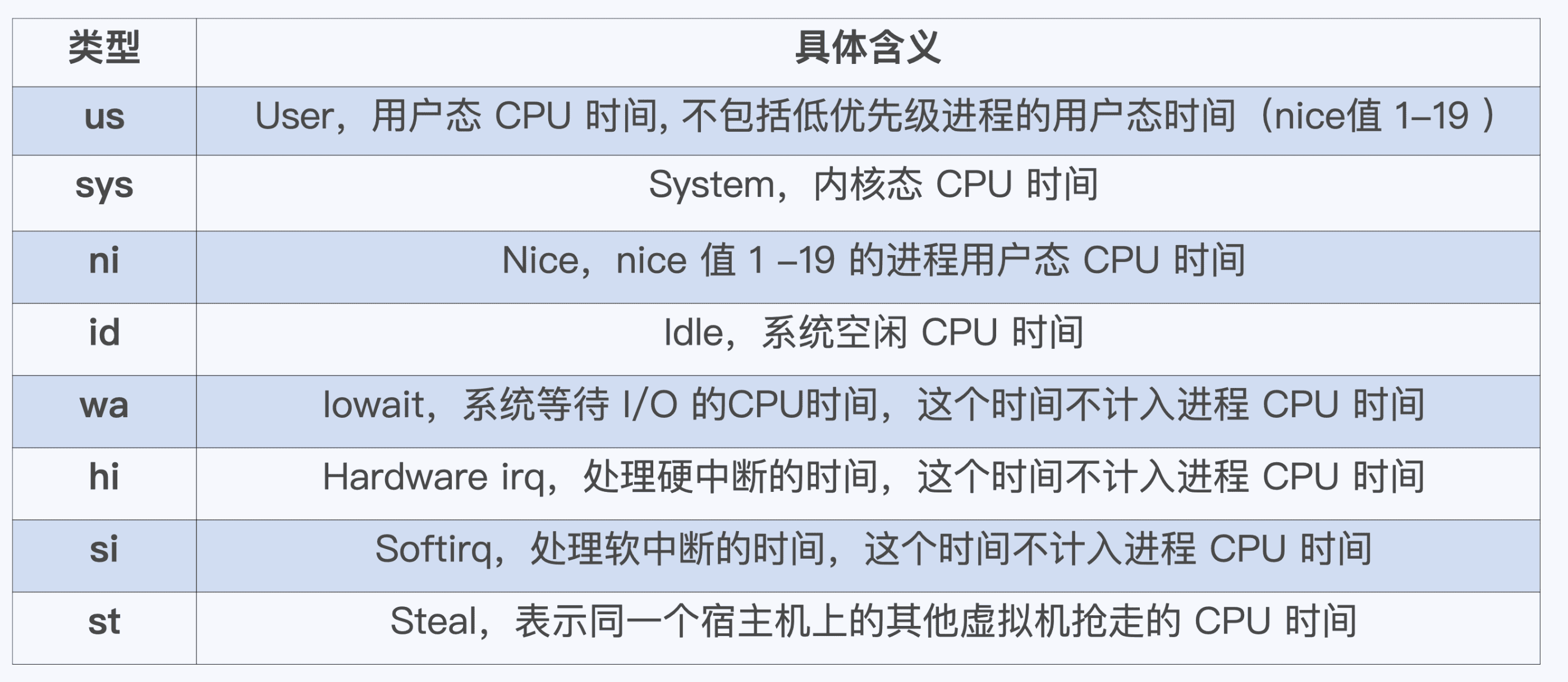
通过top命令可以直观的看到这些值:

对于Cgroup限制了CPU的控制组,Cgroup只会限制us、ni、sy的时间。对于iowait或软硬中断的wa、hi、si,是不去做限制的。
Load Average和D状态进程
在使用top命令时右上角会存在一个叫做load average的字段,后面会跟三个值,代表过去1分钟、5分钟、15分钟的load average。

在衡量机器负载时,除了CPU使用率,load average也至关重要,即使CPU使用率不高,load average升高也会造成系统变慢,从定义上看,它代表了系统一段时间内的平均负载。从计算上看,load average表示的是一段时间内运行队列中需要被调度的进程/线程,和处于TASK_UNINTERRUPTIBLE状态的进程(它的STAT是D)之和的平均数目。load average高也就代表着,这段时间内,CPU被大量占据,那么我们运行的程序自然就会变慢。
Note:
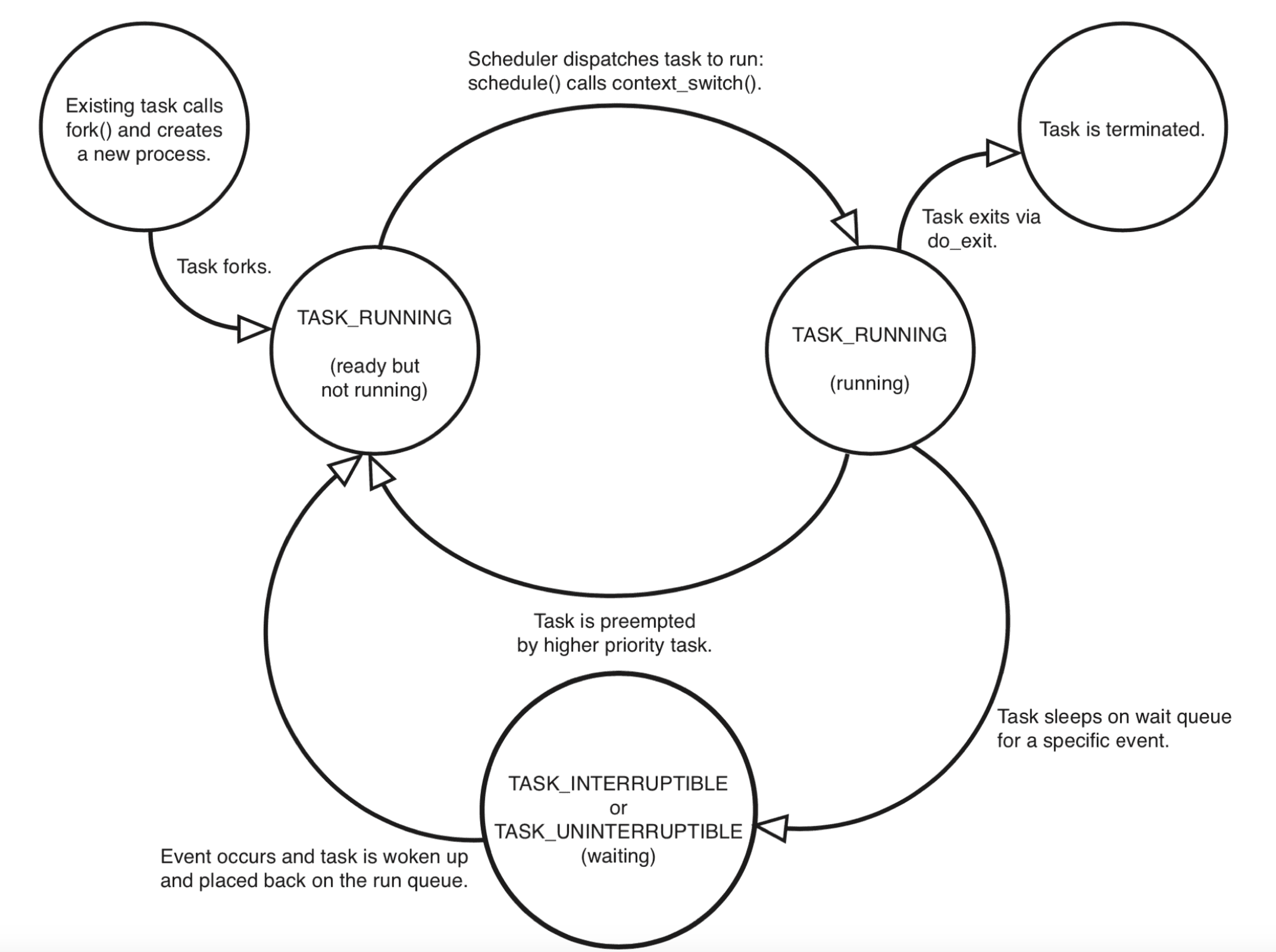
在Linux内核,进程和线程都是通过
task_stuct{}这个结构体来表示(即PCB,进程由代码+数据+PCB组成),task_struct也是Linux里基本的调度单位。一个进程从创建(fork)到退出(exit),状态的流转如下:
图中可以看出,在进程活着的时候只有运行态(TASK_RUNNING)和睡眠态(TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE)两种状态:
运行态意味着进程获得了CPU资源,进程在run queue里被调度运行,运行态的进程通过ps命令查看STAT显示R。
睡眠态则意味着进程在等待某个资源,可能是某个信号量,磁盘IO,该状态的进程会被放入wait queue中。睡眠态包含两个子状态:TASK_INTERRUPTIBLE,意味着可以被打断,比如等待socket连接,等待信号量到达等,ps命令的STAT显示为S;TASK_UNINTERRUPTIBLE,意味着不可被打断,用于防止与设备交互的过程被打断,一般时间非常短,STAT显示为D。
进程的不可中断状态是系统的一种保护机制,用于保证硬件的交互过程不被意外打断(比如在得到磁盘回复前,进程是不能被其他进程或者中断让硬件和进程数据的状态不一致)。所以,短时间的不可中断状态是很正常的。但是,当进程长时间都处于不可中断状态时,就需要确认下是不是磁盘I/O存在问题,相关的进程和磁盘设备是否工作正常。
如果容器中的D状态进程数量过多,就会造成CPU的使用量不高,但是load average升高。此时容器的CPU完全被这些不可中断的D状态进程占据,正常进程就会变慢。通过ps -aux | grep " D "可以查询容器中有多少个D状态进程。
D状态进程产生的原因,主要集中在磁盘I/O和信号量锁的访问上,基本都是对Linux里全局资源的竞争。D状态进程造成的容器性能下降的问题,Cgroups无法解决,只能通过监控D状态进程数及时发现问题,比如如果是磁盘硬件出现问题导致的D状态进程数量增加,就需要更换磁盘。如果是进程卡死在这种状态,由于D状态进程无法响应中断信号,这种情况下只能通过重启解决。
容器内存
OOM Kill
容器出现OOM(即Out of Memory),意味着容器内的进程使用的内存已经超出了Cgroup的限制,此时Linux内核为了安全就会主动杀死容器里的一个进程,如果杀死的是init进程,那么容器就会退出。
出现OOM的原因,本质上是由于Linux的内存申请策略是允许overcommit的,也就是允许进程申请超过物理内存上限的内存空间。也就是说即使内存已经不足以支持malloc()函数申请的大小,malloc()函数依然会返回成功,malloc()返回的只是一个虚拟地址,而当程序真正往这个地址写入数据时,才会分配给程序。这样的设计方式是为了尽量的提高内存的利用率,但是带来的问题就是,当进程实际使用的内存空间超过限制时,就会出现OOM。
内核针对容器OOM时采用的策略,就是杀死一个进程。那么具体杀死哪个进程,会根据公式计算出来:totalpages*oom_score_adj+points。其中totalpages是系统总的内存页面数;oom_score_adj是一个校准值,位于/proc/<pid>/oom_score_adj文件中,取值是-1000到1000之间;points则是进程已经使用的物理页面数。这个值越大,被杀死的几率越大。
所以如果希望容器的init进程尽量不退出,可以尽量调小1号进程的oom_score_adj的值。但是这并不是个好的解决方案,最好能分析出为什么会出现OOM,如果是容器的内存不足,那么就调高容器的内存限制,如果出现了内存泄漏,则需要去解决代码Bug。
Page Cache机制
Linux在用户态存在两种内存的使用类型。一种是RSS(Resident Set Size),一种是Page Cache。
RSS指进程真正申请到的物理内存页面的大小。比如通过malloc()申请一块内存,返回的是一个虚拟地址,当进程对这个地址真正执行写操作时,系统才会真正分配内存给进程,而这个过程中进程真正得到的内存就是RSS。对于一个进程来说,它实际占用的内存空间都是RSS,包括代码段、数据段、进程的task_struct{}结构体(PCB)都属于RSS。可以通过/proc/<pid>/smaps文件查看RSS的分配。
而Page Cache则是在进程对磁盘进行读写时,在内核态对磁盘内容进行缓存的一块内存,它的主要作用就是为了提高磁盘文件的读写性能。Linux的系统调用read()和write()的缺省行为都是会把读过的和写过的页面存放在Page Cache里。Linux中针对Page Cache会有一个内存回收机制,根据系统里空闲的物理内存是否低于某个阈值,决定是否需要回收一部分内存,回收的算法则是LRU,Page Cache作为缓存作用的内存空间,会被优先释放。malloc()申请内存并写入时,一旦系统发现物理内存低于阈值,则会释放LRU链表最尾部的Page Cache页,保证内存空间的充足。
Cgroup的memory控制组里的参数memory.usage_in_bytes是包括了RSS和Page Cache的,所以它不能代表进程真正使用的内存大小。要查看进程使用内存的真实值,可以通过Cgroup的memory控制组的memory.stat查看里面的cache和rss相关的值。
# cat memory.stat | grep rss
rss 428994560
rss_huge 360710144
total_rss 428994560
total_rss_huge 360710144
# cat memory.stat | grep cache
cache 63934464
total_cache 63934464Swap空间
Swap空间,就是一块磁盘空间。当内存写满的时候,就可以将一些不常用的数据暂时写到Swap空间上,以应对一些瞬时突发的内存需求。
容器中如果要使用Swap空间,需要节点上存在Swap分区,可以通过swapon --show命令查看当前有没有Swap空间,如果没有可以通过一些命令创建出一个。通过free -h则可以看到当前内存和Swap空间的使用情况。
因为容器本质也就是一堆进程,所以如果节点上存在Swap空间,那么当容器的内存不足时可以自动使用Swap空间。这里也要注意,Swap空间会让容器的内存限制被突破,使得内存泄漏问题更加不容易被发现,并且在Swap空间的读写也会降低性能,所以需要根据实际情况,谨慎使用。
那么什么时候系统会使用Swap空间呢?在文件/proc/sys/vm/swappiness中会记录一个值,代表在内存不足的时候,会如何处理Page Cache和Swap空间。swappiness这个值是一个权重,取值0-100,代表在可用的物理内存不足时,Page Cache和Swap空间的使用比例。当swappiness值是0时,就代表尽量不使用Swap空间,内存不足时尽量通过释放Page Cache获得物理内存,但不代表不会使用Swap空间,当空闲内存已经小于内存一个zone的最小空闲阈值时,还是会使用Swap空间的;而当swappiness值是100时,则代表Swap空间和Page Cache是等比使用,RSS中的一部分数据会被写入Swap空间,同时Page Cache也会释放一部分;大于0小于100则代表使用Page Cache会多一些。
在Cgroup的memory控制组里也有一个参数memory.swappiness,和/proc/sys/vm/swappiness是同样的功能,设置它可以在容器中生效,并覆盖宿主机上的全局swappiness。但是当memory.swappiness的值设为0时有所不同,这意味着容器中是禁止使用RSS写入Swap空间的,即使内存空间值已经小于了zone的最小空闲阈值。
容器存储
OverlayFS
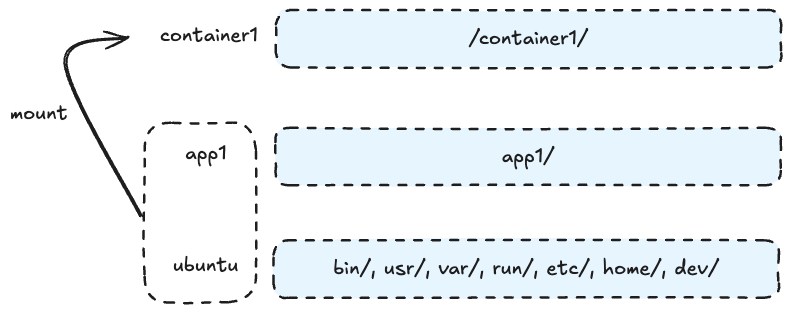
容器的文件系统其实就是它的镜像,里面会包含容器里的程序运行需要的二进制文件、库文件、配置文件,和其他的依赖文件等等。而大部分容器里的文件其实都是相同的。比如如果所有容器都基于ubuntu:latest作为基础镜像,那所有容器的文件系统都会包含ubuntu的文件系统,每个容器里的大部分文件都是相同的,只有少部分自己独有的文件。所以如果每个镜像都完整的存储在宿主机上,会存在很多冗余文件。所以为了解决这个问题,容器技术就需要选择一种针对容器的文件系统,叫做UnionFS。
UnionFS的主要功能是把多个目录(处于不同的分区)一起挂载(mount)在一个目录下。比如,把所有容器的基础镜像ubuntu:latest放在一个目录下ubuntu/,而每个容器额外的程序文件则放到另外的目录下app1/和app2/等等。这种方式明显可以节省大量的存储空间,因为容器文件系统中占大部分的ubuntu文件系统,我们只需要存一份就可以了。当容器container1启动时,我们只需要将ubuntu/目录和app1/目录一起挂载到容器的目录比如conatiner1/下就行了。如下图/。
UnionFS有很多的实现方式,比如最初Docker使用的AUFS,还有目前使用的OverlayFS。OverlayFS在Linux内核3.18版本合入主分支,也是现在大部分主流Linux发行版本里默认容器文件系统。在容器中通过df -h命令可以查看到根目录到文件系统类型为"overlay"。
# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 40G 15G 23G 39% /同样在宿主机上也能看到,每个容器对应的文件系统:
# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 916M 0 916M 0% /dev
tmpfs 936M 0 936M 0% /dev/shm
overlay 40G 15G 23G 39% /var/lib/docker/overlay2/3cec047d9bec69e913b30b1572e5e57fcc3da01e37d6bf3096f2f78b151c0240/merged
overlay 40G 15G 23G 39% /var/lib/docker/overlay2/70393d59ecd3eb9ef31012008ed8184aa70e01ae706f30425ee2b5e1cb9a5a9a/merged
overlay 40G 15G 23G 39% /var/lib/docker/overlay2/d525ad7dfc1cf12c0f16716cd7493ccef916f17674946cfe668fd093de61ad4c/mergedOverlayFS的文件系统涉及到四类目录,分别是lower、upper、merged和work。这四类目录是从下往上叠加的,每一类都是独立的层。
lower:位于最下层,这一层的文件是不会被修改的,可以认为是只读层。
upper:这一层是可读写的,基于lower层如果有文件的创删改,都会在这一层体现。
merged:这一层是挂载点目录,就是用户看到的实际的目录,也就是lower和upper的合并。
work:这一层只是一个存放临时文件的目录,一般有文件修改的中间过程会有临时文件存到这,这一层并不主要。
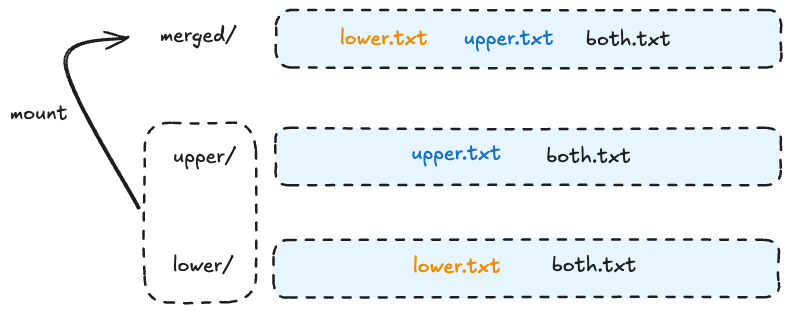
如上图,lower层的文件是不变的,upper层如果有新文件创建比如upper.txt,或者文件的修改,比如both.txt,或者还有文件删除(通过增加一个特殊文件告知OverlayFS),都会体现在这一层中,lower和upper最终合并得到merge层目录,也就是最终容器里的文件系统。
文件Quota
如上所述,对于容器中的文件系统,实际上还是挂载在宿主机上。容器中不停地写数据,实际上还是在往宿主机上写数据,所以如果容器中的进程有Bug,或者日志文件没有处理好,就会造成写满宿主机的问题,影响到宿主机上的所有容器。所以一般大量的文件写入需求,都是要通过给容器挂载Volume实现。
但是为了防止哪个容器不守规矩,就需要限制写入容器的OverlayFS的数据量。根据上述关于OverlayFS的分层,我们知道lower层文件是不会变动的,容器中写入的文件都是在upper层目录里的,那么就可以通过限制upper层目录的容量的方式,限制容器写入数据的大小。由于upper层也是一个宿主机上普通的目录,所以主要是要看宿主机支不支持限制某个目录的容量大小。
不同的Linux上的文件系统对此有不同的支持。最常用的XFS和ext4文件系统都有Quota的特性。XFS可以用Linux里的一个User、一个Group或者一个Project,来限制他们的文件使用Quota。容器场景User和Group就不太合适,可以通过Project模式实现对容器的文件系统Quota做限制。只需要给目标目录打上一个ProjectId,然后给这个ProjectId在XFS系统中设置写入数据块的限制即可,可以通过xfs_quota工具来完成。
不同的容器运行时也都是通过底层文件系统的Quota特性来实现的容器文件大小控制。
在Docker中可以通过docker run启动容器时添加--storage-opt size=<SIZE>参数对容器的大小进行限制。
在Containerd中可以通过在config.toml中配置文件大小限制。以下是一个示例,通过设置 max_size 来限制容器的文件大小:
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "overlayfs"
# 其他配置项...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v1"
# 这里可以添加其他的 runtime 配置...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# 这里可以设置 runc 的选项,比如文件大小限制
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options."max_size"]
value = "10G"磁盘限速
同一个节点上的多个容器,如果挂载同一块磁盘,那么它们相互的IO是受影响的。Cgroup v1的blkio子系统可以针对不同控制组的IO做限制,挂载点在/sys/fs/cgroup/blkio/,在下面创建子目录作为控制组,然后把需要做IO限制的pid写入到cgroup.procs中即可。然后就可以通过写一些文件来限制,主要有以下四个:
blkio.throttle.read_iops_device:代表读IOPS,即每秒钟磁盘读的次数blkio.throttle.read_bps_device:代表读bps,代表每秒钟磁盘读的吞吐量限制,bps是字节数每秒blkio.throttle.write_iops_device:代表写IOPSblkio.throttle.write_bps_device:代表写的bps
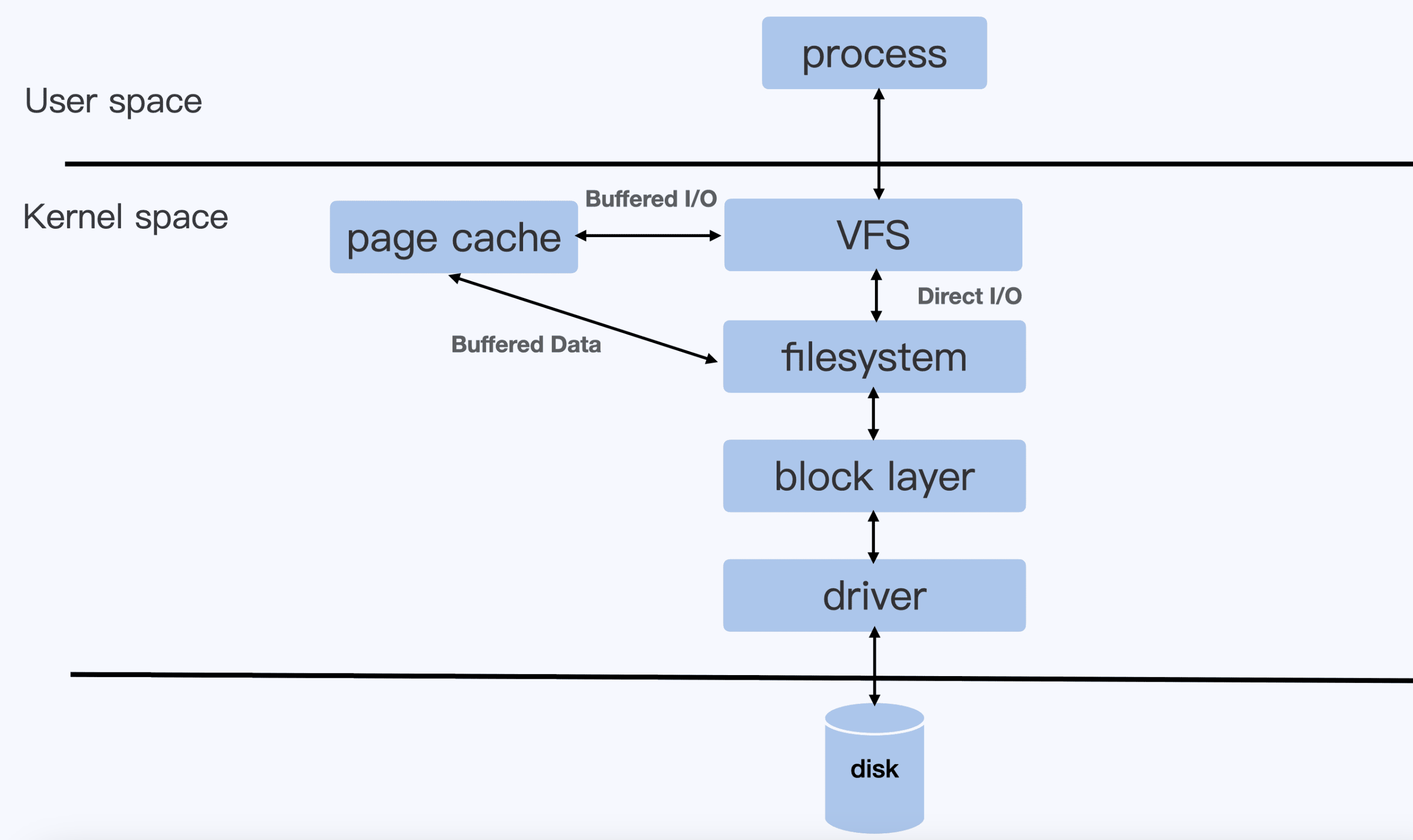
要注意的是由于Cgroup v1中各个子系统都是独立的,所以v1版本Cgroup的blkio子系统只能针对Direct I/O做限制,而涉及到内存的Buffered I/O是无法限制的。
Direct I/O和Buffered I/O
是两种Linux的文件I/O模式。
Direct I/O:可以简单理解为直接读写磁盘。就是通过Linux内核的 文件系统层(filesystem) -> 块设备层(block layer) -> 磁盘驱动 -> 磁盘硬件,每一次的I/O都会走这样一条路径。
Buffered I/O:是对Direct I/O的一种优化,可以简单理解为引入了内存作为中间层,用于提高I/O的性能。用户进程写入时,直接写入Page Cache就返回了,不必等到数据真正的写入底层磁盘,内核线程会根据内核配置周期性将脏页刷盘;读时也优先从Page Cache读,如果Page Cache中没有这块数据,会调用文件系统从磁盘读取数据,缓存到Page Cache之后,再返回给用户进程。目前绝大部分的应用都会使用Buffered I/O模式。
Cgroup v2的改进
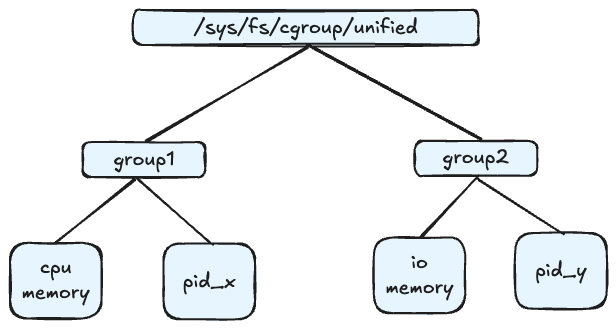
由于Cgroup v1无法对Buffered I/O做限制,所以就有了Cgroup v2。Cgroup v2相比Cgroup v1最大的变动就是把控制组从各个子系统中提到外面来。在控制组里定义自己的需要控制的多个子系统
Cgroup v1架构
Cgroup v2架构
如果要在默认为Cgroup v1的环境开启Cgroup v2作为blkio和memory的控制,可以设置内核参数cgroup_no_v1=blkio,memory,代表把Cgroup v1的blkio和memory这两个子系统禁用,那么Cgroup v2的这两个子系统就会打开了。设置完重启Linux。
Cgroup v2的目录位于/sys/fs/cgroup/unified目录下,在下面创建自己的控制组。要限制Buffered I/O,首先要开启Cgroup v2对io和memory两个子系统,将+io +memory填入到unified目录下的cgroup.subtree_control文件中。在我们的控制组里填好控制的进程id到cgroup.procs中,最后将我们需要对控制组做的限制填入到io.max文件中即可。
Kubernetes v1.24版本以上kubelet才开始支持Cgoup v2,Containerd则是在v1.5.0才较好地支持了Cgroup v2。
容器网络
Network Namespace隔离了哪些资源
Network Namespace,用于在一台Linux节点上对网络进行隔离。它主要隔离了以下种资源:
网络设备。lo、eth0、网桥、veth pair等网络设备,可以通过
ip link命令查看网络相关的内核参数。位于
/proc/sys/net/目录下的网络相关的内核参数,也就是说Network Namespace下的网络相关的内核参数和宿主机上是独立的。而创建一个Network Namespace时并不会直接继承宿主机上的相关参数值,某些参数会继承,某些则会取缺省值。IP路由表。不同的Network Namespace拥有自己独立的路由表,通过命令
ip route可以查看。防火墙规则。每个Network Namespace下都可以独立配置iptables规则。
创建一个Network Namespace可以通过unshare()系统调用,或者ip netns命令完成。通过nsenter命令可以进入到某个Network Namespace中。
网络参数则位于/proc/sys/net/目录下,容器中该目录是read-only方式mount的,所以无法修改,要修改可以通过runC的sysctl相关的接口,在容器启动的时候做配置。
在Kubernetes中如果想要对Pod的某些网络参数做修改,需要用到allowed-unsafe-sysctls特性,要在kubelet开启特性,然后在Pod中的SecurityContext里添加想要修改的网络参数。
容器的网络实现
我们使用Docker的时候都知道它提供了三种网络模式:bridge、host、none。host是使用主机网络,也就是没有独立的Network Namespace,而none是没有网络配置,需要自己完成配置,所以使用最多的还是bridge,也就是桥接模式。
桥接模式
Veth pair是常用于创建网络命名空间中的虚拟网络,允许不同命名空间中的进程通过veth pair通信。它由一对虚拟网络接口组成,这两个接口作为一条虚拟的链路连接在一起,任何通过一个接口发送的数据包都会被另一个接口接收,反之亦然。
所以桥接模式的核心就是使用veth pair,将一端放在容器中,并将名字改为eth0,另一端放在宿主机网络栈上,这样就让容器的Network Namespace和宿主机上的网络栈建立了一个对等连接,从容器里eth0发出的数据包可以立刻出现在宿主机网络栈上的veth设备上,到达veth设备的数据包也可以立刻出现在容器里。
然后就是将veth设备和eth0网卡建立连接。从veth设备发到其他宿主机上的数据包需要发送到eth0,发送到同宿主机上的其他容器的数据包也需要发送到对应的veth设备上。Docker会在宿主机上创建一个名为docker0的网桥(kubernetes中会创建名为cni0的网桥),然后veth设备在宿主机网络栈上的一端,会被插在docker0网桥上。网桥用于将多个网络连接在一起并转发数据帧。它在数据链路层工作,可以理解为就是一个虚拟的二层交换机,容器和docker0网桥一起构成了一个局域网,docker0的ip就是这个局域网的网关IP。然后通过NAT技术将数据包转移到宿主机的eth0上,比如一条iptables规则iptables -P FORWARD ACCEPT,那么docker0网桥的数据包就可以发送到eth0了。
网络地址转换(NAT),是一种将私有IP地址转换为公有IP地址的技术,通常用于路由器或防火墙中。它可以帮助多个设备共享同一个 IP 地址。它分为源网络地址转换(SNAT)和目的网络地址转换(DNAT)两种形式。SNAT通过修改数据包的源IP地址,使内部网络中的设备通过公共IP地址访问外部网络;而DNAT则通过修改数据包的目的 IP 地址,将外部请求重定向到内部网络中的特定设备或服务中。NAT功能可以通过路由器、防火墙或专门的 NAT 设备实现。
整体方案如下:

这种方式很明显因为容器中的数据包,需要经过docker0再转发到eth0上,所以性能肯定会有一定损耗,据测试,veth pair的容器网络方案相比如主机网络大概性能会降低超过10%。
使用ipvlan或macvlan的网络配置方案,则可以提供媲美主机网络的性能。
ipvlan / macvlan模式
ipvlan / macvlan,都是通过在宿主机的网络接口上,配置几个虚拟的网络接口实现。这些虚拟网络接口都可以配置独立的IP,而且这些IP可以归属于不同的Network Namespace。ipvlan和macvlan的差别在于,ipvlan的每个虚拟的网络接口和宿主机上的物理网络接口是共享mac地址的,而macvlan则给每个虚拟网络接口都配置了独立的mac地址。
ipvlan的使用需要创建ipvlan接口设备(ipvt),并将ipvlan设备放置在容器中,并改名为eth0,然后再配置ipvt的IP地址和CIDR即可。
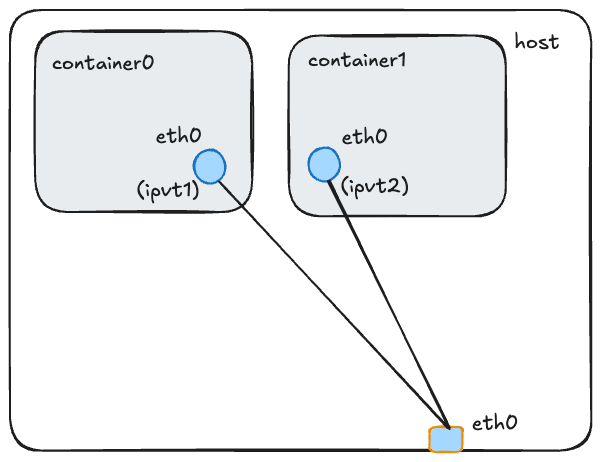
这种方式可以获得接近物理网络的性能,几乎没有损耗。
容器安全
设置合适的capabilities
Linux进程的权限可以简单分为两类,一类是特权用户的进程(用户id为0,即root用户),第二类则是非特权用户的进程(用户id非0)。特权用户可以执行Linux系统上所有的操作,而非特权用户执行某些系统级的操作时会受到限制。
从kernel 2.2开始,特权用户的"特权"被做了更详细的划分,特权的每一个子权限被称为是capability,那么对于进程来说,要做任意一个特权操作时,就需要进程的用户拥有该操作对应的capability。
比如,如果需要运行iptables命令,就需要进程拥有CAP_NET_ADMIN这个capability,如果要mount一个文件系统,就需要进程拥有CAP_SYS_ADMIN这个capability,等等。即使是root用户,如果没有对应的capabilities,也无法执行对应的操作;而即使是非root用户,只要拥有capabilities,就可以执行对应的操作。
如果一个容器配置了privileged=true,那么该容器就拥有了所有的capabilities,容器里的进程就可以执行所有的特权操作。而特权容器,即使容器中使用的root用户,系统也只允许了15个capabilities,runC对这块做了限制。
合理使用容器用户
容器可以挂载宿主机目录并修改宿主机上的关键文件,当容器中使用root用户运行进程时,那么即使容器中的root已经被限制了很多capabilities,它依然可以去修改很多宿主机上的文件。由于容器和宿主机是共享内核的,一旦软件有漏洞,就会造成安全问题。比如2019年的RunC的漏洞CVE-2019-5736,就导致容器中的root用户可以修改宿主机的runC程序,还能得到宿主机上的运行权限。
解决这个问题除了要修复软件Bug,更应该的是控制容器中的用户权限。主要有三种办法:
以普通用户运行容器
比如在Dockerfile中指定用户,或者通过Pod的securityContext中添加用户,并指定runAsNonRoot。
这种方式缺点就是不同的Pod可能指定的用户是同一个,如果要防止冲突,就得有一个额外的服务去记录每个应用使用的User Id。
使用User Namespace
User Namespace用于隔离Namespace中的用户和宿主机上的用户,它会将Namespace中的用户和宿主机上的用户建立一个映射关系。即使在Namespace中使用了root用户,也可以映射为宿主机上的普通用户。但是User Namespace在Kubernetes v1.24之后才开始支持。
这种方式的好处就是,可以预先在宿主机上把User Id创建并划分出来。然后每个服务的Pod使用自己范围内的用户即可,不会和其他服务冲突了。
以普通用户启动和管理容器
这种方式也称为rootless container。即使用非root用户启动和管理容器,即Docker或runC本身就是非root启动的,这样就不用担心runC的Bug导致容器中的用户获得宿主机的root权限了。Containerd在1.4.0版本开始引入对rootless的支持。
参考资料
[1] 极客时间《容器实战高手课》
[2] Chatgpt 3.5
评论区