


概述
Strimzi是一个K8s的Operator,用于在K8s或Openshift集群中运行Apache Kafka。提供了一种非常简单的方式来部署和管理 Kafka 集群以及相关组件(如 Zookeeper、Kafka Connect 和 Kafka MirrorMaker),几乎已经包含了围绕Kafka的完整生态。实际上Strimzi已经是一个非常成熟的Operator,被很多大公司使用,甚至在生产环境运行。作为一个纯Java实现的Operator,在一众Go开发的Operator中显得非常特别,其内部也有很多细节值得学习。
笔者之前做过Strimzi的0.25.0版本的二次开发,也参考Strimzi实现过Go基于Kubebuilder实现的Kafka Operator。这里重新读一下其代码,给一些Java开发者了解K8s的Operator提供参考,也回顾一下自己之前的工作内容。
代码结构
整个Strimzi项目是由Maven组织的,分成了很多个子Maven模块,互相之间有依赖,也有独立的工具模块。所以在git克隆完项目以后,要进行一次maven install,否则查看代码时会有很多代码飘红。由于测试代码执行时间较长,可以通过加上参数-Dmaven.test.skip=true跳过单元测试的构建和执行。
核心的模块有以下几个:
api:CRD定义的部分,如果要改CRD,需要在这里修改。从这里也可以看出,对于Operator来说,CRD就是它对外开放的API
certificate-manager:证书管理相关功能在这里。
cluster-operator:Kafka Operator的核心模块。对于Kafka集群的调谐和核心类都在这。
crd-generator:工具模块,可以根据api模块快速生成对应的CRD,非常有用。
operator-common:基础模块,存放一些基础的类,给其他模块调用的。
topic-operator:操作Kafka的Topic的Operator,让你可以通过管理集群中KafkaTopic这个CRD的方式管理集群Topic。
user-operator:类似topic-operator,同样可以通过管理KafkaUser这个CRD的方式管理集群里的User。
其中,cluster-operator子模块作为Kafka Cluster Operator的具体实现,也是我们要阅读的重点。其他的可以从这里发散开去阅读。
cluster-operator执行流程
核心类的层级结构
Operator执行的本质就是利用Informer机制,和kube-apiserver建立长连接,通过List&Watch监听CRD的变动,触发自己的调谐逻辑,调谐的目的是使对应资源的期望状态和实际状态保持一致。
Strimzi采用了Vert.x框架。Vert.x 是一个轻量级、高性能的异步应用程序框架,适合处理高并发的任务。Verticle是Vert.x框架里的基本执行单元。cluster-operator同样也是通过一个Verticle启动。
cluster-operator进行了一些Operator的拆分,分成了三层结构,不同的层级负责不同的调谐内容。拆分非常清晰,保持了高内聚低耦合,如下:
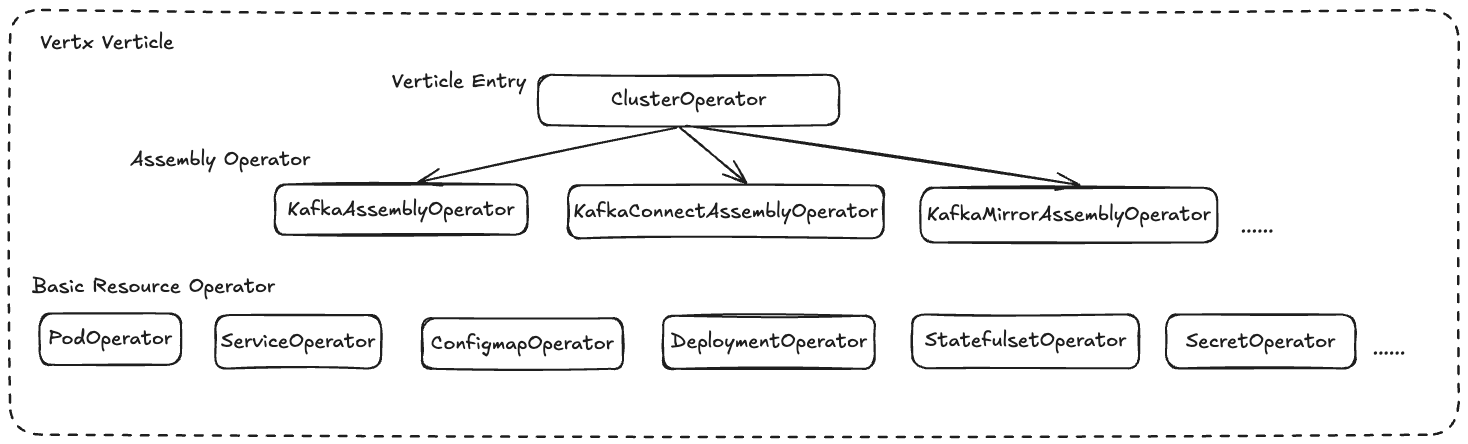
整个cluster-operator是通过Vert.x的Verticle执行,ClusterOperator作为核心类和Verticle的执行入口,ClusterOperator在启动之后,会启动其包含的各种Assembly Opertaor,比如KafkaAssemblyOperator,用于Apache Kafka集群的调谐工作;KafkaConnectAssemblyOperator,用于Kafka Connect的调谐动作,而最下层的Operator,则用于调谐各种Kubernetes的基本资源。AssemblyOperator代表着我们最关注的CRD的调谐,每个AssemblyOperator通过包装Basic Resource Operator,实现各种基本资源的调谐,并通过各种基本资源来拼装成我们想要的聚合资源,即Kafka、Kafka Connect、Kafka MirrorMaker等等。
这种划分不仅清晰直观,也非常契合组合代替继承的代码哲学:基本资源的不同组合组装成聚合资源,聚合资源组装成整个Operator。
我们这篇文章将以KafkaAssemblyOpertaor,即用于执行Apache Kafka集群调谐的Opertaor为例进行分析,因为它的底层资源最丰富,其他AssemblyOperator也是类似,逻辑会更加简单。
AssemblyOperator的启动过程
cluster-operator启动过程,以KafkaAssemblyOperator为例,各个类的执行顺序为:Main.java -> ClusterOperator.java -> AbstractOperator -> KafkaAssemblyOperator。
接下来我将去除非核心的代码,只展示核心代码,来描述启动过程。
启动Verticle
首先入口为Main类的main方法:
/**
* The main method used to run the Cluster Operator
*
* @param args The command line arguments
*/
public static void main(String[] args) {
......
// setup Micrometer metrics options
VertxOptions options = new VertxOptions().setMetricsOptions(
new MicrometerMetricsOptions()
.setPrometheusOptions(new VertxPrometheusOptions().setEnabled(true))
.setJvmMetricsEnabled(true)
.setEnabled(true));
Vertx vertx = Vertx.vertx(options);
shutdownHook.register(() -> ShutdownHook.shutdownVertx(vertx, SHUTDOWN_TIMEOUT));
......
KubernetesClient client = new OperatorKubernetesClientBuilder("strimzi-cluster-operator", strimziVersion).build();
startHealthServer(vertx, metricsProvider)
.compose(i -> leaderElection(client, config, shutdownHook))
.compose(i -> createPlatformFeaturesAvailability(vertx, client))
.compose(pfa -> deployClusterOperatorVerticles(vertx, client, metricsProvider, pfa, config, shutdownHook))
.onComplete(res -> {
if (res.failed()) {
LOGGER.error("Unable to start operator for 1 or more namespace", res.cause());
System.exit(1);
}
});
}去除掉非核心逻辑后,我们看下main方法的主体逻辑。
首先创建好Vertx对象,将用该Vertx对象去执行Verticle,然后创建好Kubernetes的客户端KubernetesClient,用于连接kube-apiserver进行CRD的监听和资源的操作。
接下来执行了一堆compose的回调。vertx的compose方法,用于连接多个异步方法,每个异步方法会在前一个异步方法执行成功后执行,任何一个异步方法失败,将会退出整个链条,最后的onComplete方法会得到compose链条的执行结果,做一些收尾处理。
所以这段代码会按照顺序启动一系列异步任务。首先会启动健康检查的HTTP Server,启动成功则执行leaderElection开启Leader选举(Operator的Leader选举通过Lease实现)。然后会执行deployClusterOperatorVerticles方法,启动ClusterOperator的Verticle。
再进入deployClusterOperatorVerticles方法查看:
/**
* Deploys the ClusterOperator verticles responsible for the actual Cluster Operator functionality. One verticle is
* started for each namespace the operator watched. In case of watching the whole cluster, only one verticle is started.
*
* @param vertx Vertx instance
* @param client Kubernetes client instance
* @param metricsProvider Metrics provider instance
* @param pfa PlatformFeaturesAvailability instance describing the Kubernetes cluster
* @param config Cluster Operator configuration
* @param shutdownHook Shutdown hook to register leader election shutdown
*
* @return Future which completes when all Cluster Operator verticles are started and running
*/
static CompositeFuture deployClusterOperatorVerticles(Vertx vertx, KubernetesClient client, MetricsProvider metricsProvider, PlatformFeaturesAvailability pfa, ClusterOperatorConfig config, ShutdownHook shutdownHook) {
ResourceOperatorSupplier resourceOperatorSupplier = new ResourceOperatorSupplier(
vertx,
client,
metricsProvider,
pfa,
config.getOperationTimeoutMs(),
config.getOperatorName()
);
......
kafkaClusterOperations = new KafkaAssemblyOperator(vertx, pfa, certManager, passwordGenerator, resourceOperatorSupplier, config);
kafkaConnectClusterOperations = new KafkaConnectAssemblyOperator(vertx, pfa, resourceOperatorSupplier, config);
kafkaMirrorMaker2AssemblyOperator = new KafkaMirrorMaker2AssemblyOperator(vertx, pfa, resourceOperatorSupplier, config);
kafkaMirrorMakerAssemblyOperator = new KafkaMirrorMakerAssemblyOperator(vertx, pfa, certManager, passwordGenerator, resourceOperatorSupplier, config);
kafkaBridgeAssemblyOperator = new KafkaBridgeAssemblyOperator(vertx, pfa, certManager, passwordGenerator, resourceOperatorSupplier, config);
kafkaRebalanceAssemblyOperator = new KafkaRebalanceAssemblyOperator(vertx, resourceOperatorSupplier, config);
.....
List<Future<String>> futures = new ArrayList<>(config.getNamespaces().size());
for (String namespace : config.getNamespaces()) {
Promise<String> prom = Promise.promise();
futures.add(prom.future());
ClusterOperator operator = new ClusterOperator(namespace,
config,
kafkaClusterOperations,
kafkaConnectClusterOperations,
kafkaMirrorMakerAssemblyOperator,
kafkaMirrorMaker2AssemblyOperator,
kafkaBridgeAssemblyOperator,
kafkaRebalanceAssemblyOperator,
resourceOperatorSupplier);
vertx.deployVerticle(operator,
res -> {
if (res.succeeded()) {
......
} else {
LOGGER.error("Cluster Operator verticle in namespace {} failed to start", namespace, res.cause());
}
prom.handle(res);
});
}
return Future.join(futures);
}去除掉非核心代码后,deployClusterOperatorVerticles方法执行过程为,首先创建了一系列的AssemblyOperator,接下来使用这些AssemblyOperator为参数创建出ClusterOperator对象。注意这里通过config.getNamespaces()获取配置中填写的所有namespace,对于每一个namespace创建对应的ClusterOperator。也就是说cluster-operator可以只监听某些namespace下的CRD,只在这些namespace下管理CR对应的Apache Kafka集群。
然后对每一个ClusterOperator使用vertx.deployVerticle方法,启动Verticle,并添加Verticle执行结束时的回调处理方法。
最后使用Future.join方法,等待所有的future结束。可以看到前面每一个ClusterOperater都对应一个future,也就是说这里类似于Go中的sync.WaitGroup,可以阻塞在这里等待所有的后台任务结束。
到这里,每个namespace下的ClusterOperator都作为一个Verticle启动。
执行Verticle
接下来跳转到ClusterOperator类,Verticle在启动时,会执行对应类的start方法,所有需要作为Verticle启动的类,也需要继承AbstractVerticle抽象类,实现start方法。还是一样,我们去除非主要逻辑,看一下ClusterOperator如何启动所有的AssmeblyOperator的。
@Override
public void start(Promise<Void> start) {
LOGGER.info("Starting ClusterOperator for namespace {}", namespace);
......
List<Future<?>> startFutures = new ArrayList<>(8);
startFutures.add(maybeStartStrimziPodSetController());
if (!config.isPodSetReconciliationOnly()) {
List<AbstractOperator<?, ?, ?, ?>> operators = new ArrayList<>(asList(
kafkaAssemblyOperator, kafkaMirrorMakerAssemblyOperator, kafkaConnectAssemblyOperator,
kafkaBridgeAssemblyOperator, kafkaMirrorMaker2AssemblyOperator, kafkaRebalanceAssemblyOperator));
for (AbstractOperator<?, ?, ?, ?> operator : operators) {
startFutures.add(operator.createWatch(namespace).compose(w -> {
LOGGER.info("Opened watch for {} operator", operator.kind());
watchByKind.put(operator.kind(), w);
return Future.succeededFuture();
}));
}
......
Future.join(startFutures)
.compose(f -> {
LOGGER.info("Setting up periodic reconciliation for namespace {}", namespace);
this.reconcileTimer = vertx.setPeriodic(this.config.getReconciliationIntervalMs(), res2 -> {
if (!config.isPodSetReconciliationOnly()) {
LOGGER.info("Triggering periodic reconciliation for namespace {}", namespace);
reconcileAll("timer");
}
});
return Future.succeededFuture((Void) null);
})
.onComplete(start);
}首先可以看到创建了一个startFutures列表,然后我们看到遍历了所有的AssemblyOperator,执行了其createWatch方法,返回的Future保存在startFutures中。createWatch方法会开启对CRD的监听。
在完成createWatch方法的启动之后,再次通过Future.join方法,等待这些createWatch启动成功以后,通过vertx.setPeriodic方法,开启了一个定时任务,定时执行reconcileAll方法,而在reconcileAll方法里面,可以看到是对每个AssemblyOperator执行其reconcileAll方法。即这个定时任务是用来定时执行全量的调谐的。
所以整体上分为两块。对于每个AssemblyOperator,启动起createWatch方法开启对CRD的监听,监听会触发其调谐动作;同时又开启了一个定时任务,定时做全量资源的调谐。
接下来我们看下KafkaAssemblyOperator的createWatch方法是如何触发AssemblyOperator的调谐动作的。
执行createWatch方法
createWatch位于AbstractOperator类,所有的AssemblyOperator都复用这段代码
/**
* Create Kubernetes watch
*
* @param namespace Namespace where to watch for resources
*
* @return A future which completes when the watcher has been created
*/
public Future<ReconnectingWatcher<T>> createWatch(String namespace) {
return VertxUtil.async(vertx, () -> new ReconnectingWatcher<>(resourceOperator, kind(), namespace, selector(), this::eventHandler));
}可以看到非常简单,这里异步执行了ReconnectingWatcher的eventHandler方法。由于监听CRD事件会阻塞,所以需要异步执行,繁殖watch阻塞主线程,否则之前的定时任务就执行不了了。
再看下eventHandler方法实现:
/**
* Event handler called when the watch receives an event.
*
* @param action An Action describing the type of the event
* @param resource The resource for which the event was triggered
*/
private void eventHandler(Watcher.Action action, T resource) {
String name = resource.getMetadata().getName();
String namespace = resource.getMetadata().getNamespace();
switch (action) {
case ADDED, DELETED, MODIFIED -> {
Reconciliation reconciliation = new Reconciliation("watch", this.kind(), namespace, name);
LOGGER.infoCr(reconciliation, "{} {} in namespace {} was {}", this.kind(), name, namespace, action);
reconcile(reconciliation);
}
case ERROR -> {
LOGGER.errorCr(new Reconciliation("watch", this.kind(), namespace, name), "Failed {} {} in namespace{} ", this.kind(), name, namespace);
reconcileAll("watch error", namespace, ignored -> {
});
}
default -> {
LOGGER.errorCr(new Reconciliation("watch", this.kind(), namespace, name), "Unknown action: {} in namespace {}", name, namespace);
reconcileAll("watch unknown", namespace, ignored -> {
});
}
}
}这里就是对监听到的事件的核心处理逻辑了。代码逻辑很简单。对于ADD、DELETED、MODIFIED类型的action,会执行reconcile方法,对该事件触发一次调谐,对于ERROR和其他事件,则会执行reconcileAll方法,启动该AssemblyOperator的全量调谐。
执行reconcile方法
AbstractOperator是所有AssemblyOperator的抽象类,所以每个AssemblyOperator都是复用的这一个reconcile方法(注意后面还有每个AssemblyOperator自己的reconcile方法,注意区分)。
**
* Reconcile assembly resources in the given namespace having the given {@code name}.
* Reconciliation works by getting the assembly resource (e.g. {@code KafkaUser})
* in the given namespace with the given name and
* comparing with the corresponding resource.
* @param reconciliation The reconciliation.
* @return A Future which is completed with the result of the reconciliation.
*/
@Override
public final Future<Void> reconcile(Reconciliation reconciliation) {
String namespace = reconciliation.namespace();
String name = reconciliation.name();
metrics().reconciliationsCounter(reconciliation.namespace()).increment();
Timer.Sample reconciliationTimerSample = Timer.start(metrics().metricsProvider().meterRegistry());
Future<Void> handler = withLock(reconciliation, LOCK_TIMEOUT_MS, () ->
resourceOperator.getAsync(namespace, name)
.compose(cr -> cr != null ? reconcileResource(reconciliation, cr) : reconcileDeletion(reconciliation)));
......
return result.future();
}该方法的核心在于withLock方法包裹住的内容。通过withLock方法,给每次触发的调谐的对象进行加锁,根据namespace加CR的name完成加锁,保证同一个CR,同一时刻,永远只能有一个线程在对它进行调谐。该锁会在本次调谐结束后释放。这也是Strimzi实现上和Go实现的Operator不一样的地方,Go的Operator是通过FIFOQueue等队列,对事件进行去重和合并,来保证多个线程不能同时对同一个CR进行调谐,Strimzi则是通过加锁实现。
withLock里面的代码则是根据CR是否为null,判断是创建修改操作,还是删除操作,分别调用reconcileResource和reconcileDeletion方法。
对于reconcileDeletion方法,内部实际上什么都没操作。因为Strimzi在创建资源时,会给同一个CR下的所有资源添加上OwnerReference字段,这样在CR被删除时,k8s的垃圾回收机制,就会自动删除掉该CR所有的子资源,所以这里Strimzi什么都不需要做。
而对于reconcileResource方法,则会最终调用到KafkaAssemblyOperator到reconcile方法,开始对Kafka的CR进行调谐。
reconcileResource方法会调用createOrUpdate,该方法是AbstractOperator的接口,每个AssemblyOperator都要实现该方法。KafkaAssemblyOperator的createOrUpdate方法如下
@Override
public Future<KafkaStatus> createOrUpdate(Reconciliation reconciliation, Kafka kafkaAssembly) {
......
reconcile(reconcileState).onComplete(reconcileResult -> {
......
if (reconcileResult.succeeded()) {
condition = new ConditionBuilder()
.withLastTransitionTime(StatusUtils.iso8601(clock.instant()))
.withType("Ready")
.withStatus("True")
.build();
// successful reconcile, write operator version to successful reconcile field
status.setOperatorLastSuccessfulVersion(OPERATOR_VERSION);
status.addCondition(condition);
createOrUpdatePromise.complete(status);
} else {
condition = new ConditionBuilder()
.withLastTransitionTime(StatusUtils.iso8601(clock.instant()))
.withType("NotReady")
.withStatus("True")
.withReason(reconcileResult.cause().getClass().getSimpleName())
.withMessage(reconcileResult.cause().getMessage())
.build();
status.addCondition(condition);
createOrUpdatePromise.fail(new ReconciliationException(status, reconcileResult.cause()));
}
});
return createOrUpdatePromise.future();
}剥离掉非核心代码后,可以看到createOrUpdate方法主要就是调用KafkaAssemblyOperator到reconcile方法,执行调谐逻辑,并在reconcile执行结束后,根据调谐的结果,更新对应的CR的Status。
KafkaAssemblyOperator的调谐过程
KafkaAssemblyOperator通过reconcile方法,来完成对Kafka这种CRD的调谐动作。代码如下:
Future<Void> reconcile(ReconciliationState reconcileState) {
Promise<Void> chainPromise = Promise.promise();
......
// only when cluster is full KRaft we can avoid reconcile ZooKeeper and not having the automatic handling of
// inter broker protocol and log message format via the version change component
reconcileState.initialStatus()
// Preparation steps => prepare cluster descriptions, handle CA creation or changes
.compose(state -> state.reconcileCas(clock))
.compose(state -> state.emitCertificateSecretMetrics())
.compose(state -> state.versionChange(kafkaMetadataConfigState.isKRaft()))
// Run reconciliations of the different components
.compose(state -> kafkaMetadataConfigState.isKRaft() ? Future.succeededFuture(state) : state.reconcileZooKeeper(clock))
.compose(state -> reconcileState.kafkaMetadataStateManager.shouldDestroyZooKeeperNodes() ? state.reconcileZooKeeperEraser() : Future.succeededFuture(state))
.compose(state -> state.reconcileKafka(clock))
.compose(state -> state.reconcileEntityOperator(clock))
.compose(state -> state.reconcileCruiseControl(clock))
.compose(state -> state.reconcileKafkaExporter(clock))
// Finish the reconciliation
.map((Void) null)
.onComplete(chainPromise);
return chainPromise.future();
}前面是关于KRaft的一些参数准备,可以不用看。核心是后面这一串的compose链条。KafkaAssemblyOperator根据这个链条,按照顺序执行不同的方法,对Kafka对象各种子资源进行调谐,来最终完成对Kafka对象的调谐。
按照顺序可以看到,链条中比较核心的是:
state.reconcileCas方法对Kafka集群的证书进行调谐;
state.reconcileZooKeeper方法,对Zookeeper集群进行调谐(如果启用了KRaft这一步是直接成功的)
state.reconcileKafka,对Kafka集群进行调谐;
state.reconcileEntityOperator,如果CR配置了TopicOperator和UserOperator,这一步将会给每个Kafka集群创建一个entityOperator的deployment,为KafkaTopic和KafkaUser这两种CRD进行调谐,即支持通过管理CR的方式管理Kafka集群的主题和用户;
state.reconcileCruiseControl,如果CR配置了CruiseControl,则启动对CruiseControl的调谐,对Kafka集群进行巡航;
state.reconcileKafkaExporter,如果CR配置了KafkaExporter,则启动对KafkaExporter的调谐,暴露监控指标。
我们以对Kafka集群的调谐的reconcileKafka方法为例进行阅读,其他子资源也都类似。reconcileKafka方法最终会走到KafkaReconciler.reconcile方法。如下:
/**
* The main reconciliation method which triggers the whole reconciliation pipeline. This is the method which is
* expected to be called from the outside to trigger the reconciliation.
*
* @param kafkaStatus The Kafka Status class for adding conditions to it during the reconciliation
* @param clock The clock for supplying the reconciler with the time instant of each reconciliation cycle.
* That time is used for checking maintenance windows
*
* @return Future which completes when the reconciliation completes
*/
public Future<Void> reconcile(KafkaStatus kafkaStatus, Clock clock) {
return modelWarnings(kafkaStatus)
.compose(i -> initClientAuthenticationCertificates())
.compose(i -> manualPodCleaning())
.compose(i -> networkPolicy())
.compose(i -> manualRollingUpdate())
.compose(i -> pvcs(kafkaStatus))
.compose(i -> serviceAccount())
.compose(i -> initClusterRoleBinding())
.compose(i -> scaleDown())
.compose(i -> updateNodePoolStatuses(kafkaStatus))
.compose(i -> listeners())
.compose(i -> certificateSecret(clock))
.compose(i -> brokerConfigurationConfigMaps())
.compose(i -> jmxSecret())
.compose(i -> podDisruptionBudget())
.compose(i -> migrateFromStatefulSetToPodSet())
.compose(i -> podSet())
.compose(podSetDiffs -> rollingUpdate(podSetDiffs)) // We pass the PodSet reconciliation result this way to avoid storing it in the instance
.compose(i -> podsReady())
.compose(i -> serviceEndpointsReady())
.compose(i -> headlessServiceEndpointsReady())
.compose(i -> clusterId(kafkaStatus))
.compose(i -> defaultKafkaQuotas())
.compose(i -> nodeUnregistration(kafkaStatus))
.compose(i -> metadataVersion(kafkaStatus))
.compose(i -> deletePersistentClaims())
.compose(i -> sharedKafkaConfigurationCleanup())
// This has to run after all possible rolling updates which might move the pods to different nodes
.compose(i -> nodePortExternalListenerStatus())
.compose(i -> addListenersToKafkaStatus(kafkaStatus))
.compose(i -> updateKafkaVersion(kafkaStatus))
.compose(i -> updateKafkaMetadataMigrationState())
.compose(i -> updateKafkaMetadataState(kafkaStatus));
}这一整个compose链条就是对Kafka集群调谐的整个逻辑了,每一步都会对某个子资源进行调谐,保证其实际状态,和根据CR中定义的期望状态保持一致。并且在Kafka集群运行后,还可以通过连接到Kafka集群,完成一些配置,最终则会将一些连接信息和集群状态更新到CR的Status中。
根据compose链条每一步的方法名,可以猜出每一步的作用。由于步骤较多,在这篇文章中无法一一展现,我们以较为简单的serviceAccount()这一步为例,看看ServiceAccount对象是如何被调谐的。
serviceAccount方法最终会调用serviceAccountOperator.reconcile方法(前面那张图中最底层的基本资源的Operator),对serviceAccount进行调谐。
/**
* Asynchronously reconciles the resource with the given namespace and name to match the given
* desired resource, returning a future for the result.
* @param reconciliation Reconciliation object
* @param namespace The namespace of the resource to reconcile
* @param name The name of the resource to reconcile
* @param desired The desired state of the resource.
* @return A future which completes when the resource has been updated.
*/
public Future<ReconcileResult<T>> reconcile(Reconciliation reconciliation, String namespace, String name, T desired) {
if (desired != null && !namespace.equals(desired.getMetadata().getNamespace())) {
return Future.failedFuture("Given namespace " + namespace + " incompatible with desired namespace " + desired.getMetadata().getNamespace());
} else if (desired != null && !name.equals(desired.getMetadata().getName())) {
return Future.failedFuture("Given name " + name + " incompatible with desired name " + desired.getMetadata().getName());
}
return getAsync(namespace, name)
.compose(current -> {
if (desired != null) {
if (current == null) {
LOGGER.debugCr(reconciliation, "{} {}/{} does not exist, creating it", resourceKind, namespace, name);
return internalCreate(reconciliation, namespace, name, desired);
} else {
LOGGER.debugCr(reconciliation, "{} {}/{} already exists, updating it", resourceKind, namespace, name);
return internalUpdate(reconciliation, namespace, name, current, desired);
}
} else {
if (current != null) {
// Deletion is desired
LOGGER.debugCr(reconciliation, "{} {}/{} exist, deleting it", resourceKind, namespace, name);
return internalDelete(reconciliation, namespace, name);
} else {
LOGGER.debugCr(reconciliation, "{} {}/{} does not exist, noop", resourceKind, namespace, name);
return Future.succeededFuture(ReconcileResult.noop(null));
}
}
});
}这里的核心就是几个判断。首先请求参数里会带有desired,是一个范形类,在这里表示期望的ServiceAccount对象。前面两个判断是对于desired无效的判断,直接返回调谐失败。之后通过getAsync方法,查询到实际的ServiceAccount对象,作为current变量,传入compose里面的方法中。接下里是核心的几个判断:
当desired不为null,而current为null时,说明ServiceAccount实际不存在,则调用internalCreate方法,使用desired对ServiceAccount进行创建;
当desired不为null,current也不为null,说明ServiceAccount期望和实际有可能不一致,则调用internalUpdate方法,将该ServiceAccount强制更新为desired;
当desired为null,current不为null时,说明ServiceAccount需要被删除,则调用internalDelete方法,删除该ServiceAccount;
当desired为null,current也为null时,则实际和期望一致,不用操作,直接返回成功。
至此我们就完成了对cluster-opeator的主体逻辑的大致梳理。
二开问题记录
以下是我在对Strimzi进行二次开发过程中碰到的一些问题的回忆。
1. Strimzi是如何判断一个Zookeeper/Kafka集群是否需要被调谐?
Strimzi通过KafkaCluster类,来保持Kafka集群的期望状态信息。每次调谐时,都会根据CR中对Kafka集群的描述内容生成一个KafkaCluster实例,然后在调谐的compose链条中,每个阶段会查询该阶段所负责的对应子资源,是否和KafkaCluster实例里的描述一致,来判断Kafka集群是否需要被调谐。
根据期望状态生成KafkaCluster对象代码在reconcileKafka方法中,创建kafkaReconciler时最终会调用到KafkaCluster.fromCrd这个静态方法,根据CR的内容完成KafkaCluster对象的创建,并把该KafkaCluster对象保存在KafkaAssemblyOperator的kafka这个字段下面,后续在cmopose调谐链条里将会被使用。
2. Kafka集群的配置是如何生成的?
Strimzi是通过ConfigMap和Kafka镜像里的启动脚本配合,来完成Kafka每个Broker的配置。
首先如问题1所述,每一次调谐时都会根据CR生成一个KafkaCluster对象,该对象里则会带有描述Kafka的broker配置的Configmap信息,Configmap里保存着Kafka broker的配置信息,KafkaCluster通过调用KafkaBrokerConfigurationBuilder这个类,来生成所有需要的配置项,比如rackId、logDirs、listeners、quotas等等,代码如下:
/**
* Internal method used to generate a Kafka configuration for given broker node.
*
* @param node Node reference with Node ID and pod name
* @param pool Pool to which this node belongs - this is used to get pool-specific settings such as storage
* @param advertisedHostnames Map with advertised hostnames
* @param advertisedPorts Map with advertised ports
*
* @return String with the Kafka broker configuration
*/
private String generatePerBrokerConfiguration(NodeRef node, KafkaPool pool, Map<Integer, Map<String, String>> advertisedHostnames, Map<Integer, Map<String, String>> advertisedPorts) {
KafkaBrokerConfigurationBuilder builder =
new KafkaBrokerConfigurationBuilder(reconciliation, node, this.kafkaMetadataConfigState)
.withRackId(rack)
.withLogDirs(VolumeUtils.createVolumeMounts(pool.storage, false))
.withListeners(cluster,
namespace,
listeners,
listenerId -> advertisedHostnames.get(node.nodeId()).get(listenerId),
listenerId -> advertisedPorts.get(node.nodeId()).get(listenerId)
)
.withAuthorization(cluster, authorization)
.withCruiseControl(cluster, ccMetricsReporter, node.broker())
.withTieredStorage(cluster, tieredStorage)
.withQuotas(cluster, quotas)
.withUserConfiguration(configuration, node.broker() && ccMetricsReporter != null);
withZooKeeperOrKRaftConfiguration(pool, node, builder);
return builder.build().trim();
}这些配置信息会保存到Configmap中,在创建Kafka集群时,被挂载到Pod中。
而我们仔细观察这里生成的配置信息,实际上是不全的,里面有很多占位符,很对配置的值没有被填写,也就是说这份配置文件实际上是不能用的。
那么Strimzi是如何将配置文件中占位符的内容填上值呢,是通过Kafka的Pod启动脚本完成的。Strimzi创建Kafka的Statefulset对象时,会将配置文件中需要的一些参数,放入Pod的环境变量中。然后在Pod启动时,执行启动脚本,会根据挂载的Configmap重新生成一份配置文件,从环境变量中取出注入的配置项的值,将这些值,替换掉新配置文件里的占位符,并且Kafka的broker启动时,指定的也是这个新的配置文件。
也就是说Configmap里保存的只是一个带有占位符的配置的模板,Kafka的broker启动时,会复制这个配置文件,并填好文件里占位符的内容。
Strimzi这样设计的原因,应该是为了保持Configmap的一致,并且有些参数,在部署broker时还不能确定,只能等到broker启动时才能拿到值。
3. 调谐时如何忽略掉某些字段的不一致
在实际开发中遇到过这样一个问题。我在集群中使用Strimzi创建好了一个Kafka集群,但是它的所有Pod都不停在重启。观察Strimzi-Cluster-Operator的日志发现所有的重启动作都是由Operator触发的,让我觉得很困惑,因为并没有人修改过Kafka集群的CR,在这个集群已经稳定以后为什么又会出现集群的实际状态和期望状态不一致的情况呢。
我开启Operator的debug日志,并逐条分析后,发现是触发Pod重启的原因是由于Pod的某个Annotation,实际和期望不一致,经过调查,发现是K8s集群里部署了一个Mutating Webhook,它会给Pod加上一些Annotations。而Strimzi生成期望对象是完全根据CR创建的,不会带有这些Annotation,所以Strimzi就会认为Pod的实际状态和期望状态不一致了,根据代码逻辑就会导致RollingUpdate,造成Pod重启。
那么为了避免这个问题,就需要让Strimzi忽略掉Pod的某些Annotation的不一致,在深入分析源码后,我找到了解决方案。实际上Strimzi在判断资源的实际状态和期望状态到底有没有差别时,引入了一个叫做**Diff的类,很多资源比如Service、Storage等, 都会使用对应的**Diff类,来对资源实际状态和期望状态进行比较。对于Pod来说,实际上是通过StatefulsetDiff这个类来完成的。Statefulset的调谐逻辑,和前文提到的ServiceAccount的调谐逻辑类似,都是单纯检查desired和current两个对象是否都不会null,如果都不为null,则会执行internalUpdate方法,尝试对Statefulset进行更新,而StatefulsetOperator的internalUpdate方法,会先生成一个名为diff的StatefulsetDiff对象,diff中会记录Statefulset的实际和期望差异在哪,然后会根据diff中具体的差异字段在哪,决定是否要进行RollingUpdate,比如是否有label的更新,是否有volume的变化等。那么我们希望调谐时能忽略掉某些Annotation,只需要修改StatefulsetDiff这个类,判断差异时忽略某些Annotation即可。
StatefulsetDiff类下面实际上已经有很多默认会忽略的字段了,记录在IGNORABLE_PATH下,我们希望忽略什么养的鹅字段,只需要填在这里即可,
public class StatefulSetDiff extends AbstractJsonDiff {
private static final ReconciliationLogger LOGGER = ReconciliationLogger.create(StatefulSetDiff.class.getName());
......
private static final Pattern IGNORABLE_PATHS = Pattern.compile(
"^(/metadata/managedFields"
+ "|/metadata/creationTimestamp"
+ "|/metadata/resourceVersion"
+ "|/metadata/generation"
+ "|/metadata/uid"
+ "|/spec/revisionHistoryLimit"
+ "|/spec/template/metadata/annotations/" + SHORTENED_STRIMZI_DOMAIN + "~1generation"
+ "|/spec/template/spec/initContainers/[0-9]+/resources"
+ "|/spec/template/spec/initContainers/[0-9]+/terminationMessagePath"
+ "|/spec/template/spec/initContainers/[0-9]+/terminationMessagePolicy"
+ "|/spec/template/spec/initContainers/[0-9]+/env/[0-9]+/valueFrom/fieldRef/apiVersion"
+ "|/spec/template/spec/containers/[0-9]+/resources"
+ "|/spec/template/spec/containers/[0-9]+/env/[0-9]+/valueFrom/fieldRef/apiVersion"
+ "|/spec/template/spec/containers/[0-9]+/livenessProbe/failureThreshold"
+ "|/spec/template/spec/containers/[0-9]+/livenessProbe/periodSeconds"
+ "|/spec/template/spec/containers/[0-9]+/livenessProbe/successThreshold"
+ "|/spec/template/spec/containers/[0-9]+/readinessProbe/failureThreshold"
+ "|/spec/template/spec/containers/[0-9]+/readinessProbe/periodSeconds"
+ "|/spec/template/spec/containers/[0-9]+/readinessProbe/successThreshold"
+ "|/spec/template/spec/containers/[0-9]+/terminationMessagePath"
+ "|/spec/template/spec/containers/[0-9]+/terminationMessagePolicy"
+ "|/spec/template/spec/dnsPolicy"
+ "|/spec/template/spec/restartPolicy"
+ "|/spec/template/spec/securityContext"
+ "|/spec/template/spec/volumes/[0-9]+/configMap/defaultMode"
+ "|/spec/template/spec/volumes/[0-9]+/secret/defaultMode"
+ "|/spec/volumeClaimTemplates/[0-9]+/status"
+ "|/spec/volumeClaimTemplates/[0-9]+/spec/volumeMode"
+ "|/spec/volumeClaimTemplates/[0-9]+/spec/dataSource"
+ "|/spec/template/spec/serviceAccount"
+ "|/status)$");
......而比较两个对象的方法,在StatefulsetDiff的构造方法里,如果需要更细致的字段忽略逻辑,在这里进行定制化修改即可。
/**
* Constructor
*
* @param reconciliation Reconciliation marker
* @param current Current StatefulSet
* @param desired Desired StatefulSet
*/
public StatefulSetDiff(Reconciliation reconciliation, StatefulSet current, StatefulSet desired) {
JsonNode source = PATCH_MAPPER.valueToTree(current);
JsonNode target = PATCH_MAPPER.valueToTree(desired);
JsonNode diff = JsonDiff.asJson(source, target);
int num = 0;
boolean changesVolumeClaimTemplate = false;
boolean changesVolumeSize = false;
boolean changesSpecTemplate = false;
boolean changesLabels = false;
boolean changesSpecReplicas = false;
for (JsonNode d : diff) {
String pathValue = d.get("path").asText();
if (IGNORABLE_PATHS.matcher(pathValue).matches()) {
ObjectMeta md = current.getMetadata();
LOGGER.debugCr(reconciliation, "StatefulSet {}/{} ignoring diff {}", md.getNamespace(), md.getName(), d);
continue;
}
Matcher resourceMatchers = RESOURCE_PATH.matcher(pathValue);
if (resourceMatchers.matches()) {
if ("replace".equals(d.path("op").asText())) {
boolean same = compareMemoryAndCpuResources(source, target, pathValue, resourceMatchers);
if (same) {
ObjectMeta md = current.getMetadata();
LOGGER.debugCr(reconciliation, "StatefulSet {}/{} ignoring diff {}", md.getNamespace(), md.getName(), d);
continue;
}
}
}
if (LOGGER.isDebugEnabled()) {
ObjectMeta md = current.getMetadata();
LOGGER.debugCr(reconciliation, "StatefulSet {}/{} differs: {}", md.getNamespace(), md.getName(), d);
LOGGER.debugCr(reconciliation, "Current StatefulSet path {} has value {}", pathValue, lookupPath(source, pathValue));
LOGGER.debugCr(reconciliation, "Desired StatefulSet path {} has value {}", pathValue, lookupPath(target, pathValue));
}
num++;
// Any volume claim template changes apart from size change should trigger rolling update
// Size changes should not trigger rolling update. Therefore we need to separate these two in the diff.
changesVolumeClaimTemplate |= equalsOrPrefix("/spec/volumeClaimTemplates", pathValue) && !VOLUME_SIZE.matcher(pathValue).matches();
changesVolumeSize |= isVolumeSizeChanged(pathValue, source, target);
// Change changes to /spec/template/spec, except to imagePullPolicy, which gets changed
// by k8s
changesSpecTemplate |= equalsOrPrefix("/spec/template", pathValue);
changesLabels |= equalsOrPrefix("/metadata/labels", pathValue);
changesSpecReplicas |= equalsOrPrefix("/spec/replicas", pathValue);
}
this.isEmpty = num == 0;
this.changesLabels = changesLabels;
this.changesSpecReplicas = changesSpecReplicas;
this.changesSpecTemplate = changesSpecTemplate;
this.changesVolumeClaimTemplate = changesVolumeClaimTemplate;
this.changesVolumeSize = changesVolumeSize;
}
评论区