


概览
Raft是基于Paxos算法改进而来,通过简单的设计和清晰的角色划分,提供了一种可靠且易于理解的方法来实现分布式系统中的数据一致性。Raft理论与设计细节可以查看上一篇文章:分布式协议和算法总结#Raft算法。本篇文章我们详细分析Raft的一个成熟的开源实现 Hashicorp Raft ,分析其源码实现逻辑,深入学习Raft算法,并可基于其实现一个分布式KV系统。
源码分析
github.com/hashicorp/raft包,提供了一些API帮助我们构建基于Raft协议的分布式系统。它的api.go文件中包装了一些对外开放的接口,核心逻辑则位于raft.go文件,核心结构体是Raft,代表着一个Raft集群的节点,它的构造方法如下:
Raft初始化
// NewRaft is used to construct a new Raft node. It takes a configuration, as well
// as implementations of various interfaces that are required. If we have any
// old state, such as snapshots, logs, peers, etc, all those will be restored
// when creating the Raft node.
func NewRaft(conf *Config, fsm FSM, logs LogStore, stable StableStore, snaps SnapshotStore, trans Transport) (*Raft, error) {
// Validate the configuration.
if err := ValidateConfig(conf); err != nil {
return nil, err
}
// Ensure we have a LogOutput.
logger := conf.getOrCreateLogger()
// Try to restore the current term.
currentTerm, err := stable.GetUint64(keyCurrentTerm)
if err != nil && err.Error() != "not found" {
return nil, fmt.Errorf("failed to load current term: %v", err)
}
// Read the index of the last log entry.
lastIndex, err := logs.LastIndex()
if err != nil {
return nil, fmt.Errorf("failed to find last log: %v", err)
}
// Get the last log entry.
var lastLog Log
if lastIndex > 0 {
if err = logs.GetLog(lastIndex, &lastLog); err != nil {
return nil, fmt.Errorf("failed to get last log at index %d: %v", lastIndex, err)
}
}
// Make sure we have a valid server address and ID.
protocolVersion := conf.ProtocolVersion
localAddr := trans.LocalAddr()
localID := conf.LocalID
// TODO (slackpad) - When we deprecate protocol version 2, remove this
// along with the AddPeer() and RemovePeer() APIs.
if protocolVersion < 3 && string(localID) != string(localAddr) {
return nil, fmt.Errorf("when running with ProtocolVersion < 3, LocalID must be set to the network address")
}
// Buffer applyCh to MaxAppendEntries if the option is enabled
applyCh := make(chan *logFuture)
if conf.BatchApplyCh {
applyCh = make(chan *logFuture, conf.MaxAppendEntries)
}
_, transportSupportPreVote := trans.(WithPreVote)
// Create Raft struct.
r := &Raft{
protocolVersion: protocolVersion,
applyCh: applyCh,
fsm: fsm,
fsmMutateCh: make(chan interface{}, 128),
fsmSnapshotCh: make(chan *reqSnapshotFuture),
leaderCh: make(chan bool, 1),
localID: localID,
localAddr: localAddr,
logger: logger,
logs: logs,
configurationChangeCh: make(chan *configurationChangeFuture),
configurations: configurations{},
rpcCh: trans.Consumer(),
snapshots: snaps,
userSnapshotCh: make(chan *userSnapshotFuture),
userRestoreCh: make(chan *userRestoreFuture),
shutdownCh: make(chan struct{}),
stable: stable,
trans: trans,
verifyCh: make(chan *verifyFuture, 64),
configurationsCh: make(chan *configurationsFuture, 8),
bootstrapCh: make(chan *bootstrapFuture),
observers: make(map[uint64]*Observer),
leadershipTransferCh: make(chan *leadershipTransferFuture, 1),
leaderNotifyCh: make(chan struct{}, 1),
followerNotifyCh: make(chan struct{}, 1),
mainThreadSaturation: newSaturationMetric([]string{"raft", "thread", "main", "saturation"}, 1*time.Second),
preVoteDisabled: conf.PreVoteDisabled || !transportSupportPreVote,
}
if !transportSupportPreVote && !conf.PreVoteDisabled {
r.logger.Warn("pre-vote is disabled because it is not supported by the Transport")
}
r.conf.Store(*conf)
// Initialize as a follower.
r.setState(Follower)
// Restore the current term and the last log.
r.setCurrentTerm(currentTerm)
r.setLastLog(lastLog.Index, lastLog.Term)
// Attempt to restore a snapshot if there are any.
if err := r.restoreSnapshot(); err != nil {
return nil, err
}
// Scan through the log for any configuration change entries.
snapshotIndex, _ := r.getLastSnapshot()
for index := snapshotIndex + 1; index <= lastLog.Index; index++ {
var entry Log
if err := r.logs.GetLog(index, &entry); err != nil {
r.logger.Error("failed to get log", "index", index, "error", err)
panic(err)
}
if err := r.processConfigurationLogEntry(&entry); err != nil {
return nil, err
}
}
r.logger.Info("initial configuration",
"index", r.configurations.latestIndex,
"servers", hclog.Fmt("%+v", r.configurations.latest.Servers))
// Setup a heartbeat fast-path to avoid head-of-line
// blocking where possible. It MUST be safe for this
// to be called concurrently with a blocking RPC.
trans.SetHeartbeatHandler(r.processHeartbeat)
if conf.skipStartup {
return r, nil
}
// Start the background work.
r.goFunc(r.run)
r.goFunc(r.runFSM)
r.goFunc(r.runSnapshots)
return r, nil
}可以看到NewRaft方法接收了六个参数,这些也是Raft集群的核心的几个功能模块。
Config:保存该Raft节点的配置信息,该对象可以通过DefaultConfig()方法创建默认的配置,相关字段有协议的版本号,Leader心跳的超时时间,选举超时时间,提交超时时间,一次可以提交的日志项数量,执行快照的间隔和日志数量等等。
FSM:即有限状态机,根据之前我们对Raft协议的学习,在Leader把日志复制给大多数Follower之后,会把日志项提交给状态机,来执行日志项中的实际指令。这个接口需要我们自己根据数据不同的存储需要自行实现,主要需要实现三个方法:Apply、Snapshot,和Restore。
Apply:Apply方法就是执行日志项的方法,需要保证该方法的确定性,保证在不同节点上执行相同的输入,应该产生相同的输出,保证状态的一致性(这也是有限状态机的定义)。
Snapshot:Snapshot方法用于取得当前存储的日志项的快照(也就是当前存储中的实际的数据内容),用于后面的SnapshotStore模块来进行日志的压缩以节约磁盘,他会根据配置中的执行快照的时间间隔和日志数量上限被调用。这个方法因为会阻塞Apply方法,所以需要尽可能快的返回,也就意味着该方法在取得快照后,如果有重的IO操作需要放到异步执行。
Restore:Restore方法一般是在节点重启时,需要从快照文件中恢复FSM的状态,该方法会阻塞其他方法。
LogStore:用来执行存储Raft日志的执行者,Hashicorp提供了一个raft-boltdb的底层持久化存储,来帮助我们保存Raft日志。
StableStore:用来存储Raft集群的节点信息这些关键元数据的,比如节点信息,当前的任期编号,索引信息等。同样也可以使用raft-boltdb来进行持久化存储。
SnapshotStore:用于存储快照信息,也就是压缩后的日志,Hashicorp提供了三种快照存储实现方式:
DiscardSnapshotStore:也就是不存储快照,相当于
/dev/null。FileSnapshotStore:使用文件存储,也是用的最多的。
InmemSnapshotStore:使用内存存储。
Transport:则是用于Raft节点之间的通信方式,也是一个接口,Hashicorp提供了两种实现可以直接用:
NetworkTransport:不同节点通过网络通信,比如基于TCP协议的TCPTransport,也可以使用别的网络协议,需要自己实现。
InMemTransport:通过内存通信,在内存中通过Channel通信,这种方式一般用于测试。
接下来我们继续看Raft的构造方法。可以看到首先进行了配置的校验,然后初始化Logger,然后从StableStore中取出当前的任期Term,从LogStore中取出最后一条日志项的索引,然后检查协议版本。
接下来创建了一个applyCh的Channel,根据配置中的MaxAppendEntries,也就是一次可以提交的日志项数量,来确定applyCh的容量。也就是说日志项是会被先丢到applyCh中,然后再批量的提交给FSM。
接下来使用前面创建的对象为参数,来构造一个Raft对象。
接下来初始化当前Raft节点为Follwer,根据之前我们学习的Raft协议内容,所有节点起始时都是Follower角色,然后设置了当前任期,最后一条日志的索引,然后如果有Snapshot的情况,要使用Snapshot进行数据恢复。
然后将Raft.processHeartbeat方法注册到Heatbeat请求的Handler,实际上processHeartbeat方法只是判断,如果是AppendEntries类型的RPC请求,则调用LogStore执行日志项的持久化。
最后启动了三个goroutine,分别执行run、runFSM,和runSnapshots方法:
run:就是Raft的主体逻辑,主要就是根据节点不同角色:Leader、Follower,Candidate,执行不同的逻辑。
runFSM:用于持续的从Raft的fsmMutateCh和fsmSnapshotCh中取出需要提交给FSM的操作,并最终调用FSM的Apply方法和Snapshot方法执行对应的操作。
runSnapshots:用于周期性地或者用户主动触发的执行快照操作,并且会将快照请求丢到fsmSnapshotCh中,等待FSM执行完成Snapshot方法生成快照后,调用SnapshotStore的Create方法完成快照的创建。
接下来我们详细看下这三个核心的方法。
run方法
// run the main thread that handles leadership and RPC requests.
func (r *Raft) run() {
for {
// Check if we are doing a shutdown
select {
case <-r.shutdownCh:
// Clear the leader to prevent forwarding
r.setLeader("", "")
return
default:
}
switch r.getState() {
case Follower:
r.runFollower()
case Candidate:
r.runCandidate()
case Leader:
r.runLeader()
}
}
}run方法十分简单,只是根据当前Raft节点不同的角色,执行对应方法。
runFollower()
所有Raft节点启动时都是Follower角色,所以我们先看runFollower的执行逻辑:
// runFollower runs the main loop while in the follower state.
func (r *Raft) runFollower() {
didWarn := false
leaderAddr, leaderID := r.LeaderWithID()
r.logger.Info("entering follower state", "follower", r, "leader-address", leaderAddr, "leader-id", leaderID)
metrics.IncrCounter([]string{"raft", "state", "follower"}, 1)
heartbeatTimer := randomTimeout(r.config().HeartbeatTimeout)
for r.getState() == Follower {
r.mainThreadSaturation.sleeping()
select {
case rpc := <-r.rpcCh:
r.mainThreadSaturation.working()
r.processRPC(rpc)
case c := <-r.configurationChangeCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
c.respond(ErrNotLeader)
case a := <-r.applyCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
a.respond(ErrNotLeader)
case v := <-r.verifyCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
v.respond(ErrNotLeader)
case ur := <-r.userRestoreCh:
r.mainThreadSaturation.working()
// Reject any restores since we are not the leader
ur.respond(ErrNotLeader)
case l := <-r.leadershipTransferCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
l.respond(ErrNotLeader)
case c := <-r.configurationsCh:
r.mainThreadSaturation.working()
c.configurations = r.configurations.Clone()
c.respond(nil)
case b := <-r.bootstrapCh:
r.mainThreadSaturation.working()
b.respond(r.liveBootstrap(b.configuration))
case <-r.leaderNotifyCh:
// Ignore since we are not the leader
case <-r.followerNotifyCh:
heartbeatTimer = time.After(0)
case <-heartbeatTimer:
r.mainThreadSaturation.working()
// Restart the heartbeat timer
hbTimeout := r.config().HeartbeatTimeout
heartbeatTimer = randomTimeout(hbTimeout)
// Check if we have had a successful contact
lastContact := r.LastContact()
if time.Since(lastContact) < hbTimeout {
continue
}
// Heartbeat failed! Transition to the candidate state
lastLeaderAddr, lastLeaderID := r.LeaderWithID()
r.setLeader("", "")
if r.configurations.latestIndex == 0 {
if !didWarn {
r.logger.Warn("no known peers, aborting election")
didWarn = true
}
} else if r.configurations.latestIndex == r.configurations.committedIndex &&
!hasVote(r.configurations.latest, r.localID) {
if !didWarn {
r.logger.Warn("not part of stable configuration, aborting election")
didWarn = true
}
} else {
metrics.IncrCounter([]string{"raft", "transition", "heartbeat_timeout"}, 1)
if hasVote(r.configurations.latest, r.localID) {
r.logger.Warn("heartbeat timeout reached, starting election", "last-leader-addr", lastLeaderAddr, "last-leader-id", lastLeaderID)
r.setState(Candidate)
return
} else if !didWarn {
r.logger.Warn("heartbeat timeout reached, not part of a stable configuration or a non-voter, not triggering a leader election")
didWarn = true
}
}
case <-r.shutdownCh:
return
}
}
}runFollower方法可以看到首先打了关于该节点的角色、配置等信息。然后初始化了heartbeatTimer这个Channel,该Channel将在心跳超时时得到通知。然后陷入一个for-select的多路复用中,进行周期性的信息处理。
在接下来的代码中可以看,首先执行了r.mainThreadSaturation.sleeping()方法,然后在每一个Channel监听到消息后,都会执行r.mainThreadSaturation.working()。mainThreadSaturation这个对象是用于统计主协程的工作饱和度的,sleeping()方法用于通知该协程进入不工作的睡眠状态,working()方法则用于通知该协程进入工作状态中。
接下来是大量的对不同Channel的消息处理。可以看到对于需要Leader节点处理的消息是直接返回错误或者直接忽略,而需要Follower角色处理的核心的Channel有下面两个:
rpcCh:处理接收到的RPC请求,根据不同的请求类型做处理,比如复制日志和心跳的请求AppendEntriesRequest、投票的请求RequestVoteRequest、根据发来的快照初始化本地状态机的请求InstallSnapshotRequest,等等。
heartbeatTimer:处理心跳超时,当这个Channel收到消息时,就是Follower到达了心跳超时时间,此时如果在这超时期间内没有收到Leader的消息,则此时Follower需要转换为Candidate,并开启Leader选举和推出runFollower方法。
RPC请求的处理我们稍后再仔细看,这里先主要分析下心跳超时的处理。如上的代码中可以看到,在接收到heartbeatTimer的消息后,首先会重置heartbeatTimer,然后判断Leader最近一次联系Follower的时间,是否超过了配置的心跳超时时间,没超过则跳过,超过了则会进行如下的处理:
判断latestIndex是否是0,如果是0证明此时该节点没有任何日志,并且didWarn为True说明该节点是刚启动的状态,则该节点跳过不参与此次选举;
判断当前节点的最新一条日志项是否已完成提交(即本地的日志),并且本地节点不是Voter(本地节点有投票权),则跳过;
否则,则转换当前节点状态为Candidate,并退出循环,回到run()方法中。
接下来,由于当前节点已转换为Candidate,将会执行runCandidate()方法。
runCandidate()
// runCandidate runs the main loop while in the candidate state.
func (r *Raft) runCandidate() {
term := r.getCurrentTerm() + 1
r.logger.Info("entering candidate state", "node", r, "term", term)
metrics.IncrCounter([]string{"raft", "state", "candidate"}, 1)
// Start vote for us, and set a timeout
var voteCh <-chan *voteResult
var prevoteCh <-chan *preVoteResult
// check if pre-vote is active and that this is not a leader transfer.
// Leader transfer do not perform prevote by design
if !r.preVoteDisabled && !r.candidateFromLeadershipTransfer.Load() {
prevoteCh = r.preElectSelf()
} else {
voteCh = r.electSelf()
}
// Make sure the leadership transfer flag is reset after each run. Having this
// flag will set the field LeadershipTransfer in a RequestVoteRequst to true,
// which will make other servers vote even though they have a leader already.
// It is important to reset that flag, because this priviledge could be abused
// otherwise.
defer func() { r.candidateFromLeadershipTransfer.Store(false) }()
electionTimeout := r.config().ElectionTimeout
electionTimer := randomTimeout(electionTimeout)
// Tally the votes, need a simple majority
preVoteGrantedVotes := 0
preVoteRefusedVotes := 0
grantedVotes := 0
votesNeeded := r.quorumSize()
r.logger.Debug("calculated votes needed", "needed", votesNeeded, "term", term)
for r.getState() == Candidate {
r.mainThreadSaturation.sleeping()
select {
case rpc := <-r.rpcCh:
r.mainThreadSaturation.working()
r.processRPC(rpc)
case preVote := <-prevoteCh:
// This a pre-vote case it should trigger a "real" election if the pre-vote is won.
r.mainThreadSaturation.working()
r.logger.Debug("pre-vote received", "from", preVote.voterID, "term", preVote.Term, "tally", preVoteGrantedVotes)
// Check if the term is greater than ours, bail
if preVote.Term > term {
r.logger.Debug("pre-vote denied: found newer term, falling back to follower", "term", preVote.Term)
r.setState(Follower)
r.setCurrentTerm(preVote.Term)
return
}
// Check if the preVote is granted
if preVote.Granted {
preVoteGrantedVotes++
r.logger.Debug("pre-vote granted", "from", preVote.voterID, "term", preVote.Term, "tally", preVoteGrantedVotes)
} else {
preVoteRefusedVotes++
r.logger.Debug("pre-vote denied", "from", preVote.voterID, "term", preVote.Term, "tally", preVoteGrantedVotes)
}
// Check if we've won the pre-vote and proceed to election if so
if preVoteGrantedVotes >= votesNeeded {
r.logger.Info("pre-vote successful, starting election", "term", preVote.Term,
"tally", preVoteGrantedVotes, "refused", preVoteRefusedVotes, "votesNeeded", votesNeeded)
preVoteGrantedVotes = 0
preVoteRefusedVotes = 0
electionTimer = randomTimeout(electionTimeout)
prevoteCh = nil
voteCh = r.electSelf()
}
// Check if we've lost the pre-vote and wait for the election to timeout so we can do another time of
// prevote.
if preVoteRefusedVotes >= votesNeeded {
r.logger.Info("pre-vote campaign failed, waiting for election timeout", "term", preVote.Term,
"tally", preVoteGrantedVotes, "refused", preVoteRefusedVotes, "votesNeeded", votesNeeded)
}
case vote := <-voteCh:
r.mainThreadSaturation.working()
// Check if the term is greater than ours, bail
if vote.Term > r.getCurrentTerm() {
r.logger.Debug("newer term discovered, fallback to follower", "term", vote.Term)
r.setState(Follower)
r.setCurrentTerm(vote.Term)
return
}
// Check if the vote is granted
if vote.Granted {
grantedVotes++
r.logger.Debug("vote granted", "from", vote.voterID, "term", vote.Term, "tally", grantedVotes)
}
// Check if we've become the leader
if grantedVotes >= votesNeeded {
r.logger.Info("election won", "term", vote.Term, "tally", grantedVotes)
r.setState(Leader)
r.setLeader(r.localAddr, r.localID)
return
}
case c := <-r.configurationChangeCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
c.respond(ErrNotLeader)
case a := <-r.applyCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
a.respond(ErrNotLeader)
case v := <-r.verifyCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
v.respond(ErrNotLeader)
case ur := <-r.userRestoreCh:
r.mainThreadSaturation.working()
// Reject any restores since we are not the leader
ur.respond(ErrNotLeader)
case l := <-r.leadershipTransferCh:
r.mainThreadSaturation.working()
// Reject any operations since we are not the leader
l.respond(ErrNotLeader)
case c := <-r.configurationsCh:
r.mainThreadSaturation.working()
c.configurations = r.configurations.Clone()
c.respond(nil)
case b := <-r.bootstrapCh:
r.mainThreadSaturation.working()
b.respond(ErrCantBootstrap)
case <-r.leaderNotifyCh:
// Ignore since we are not the leader
case <-r.followerNotifyCh:
if electionTimeout != r.config().ElectionTimeout {
electionTimeout = r.config().ElectionTimeout
electionTimer = randomTimeout(electionTimeout)
}
case <-electionTimer:
r.mainThreadSaturation.working()
// Election failed! Restart the election. We simply return,
// which will kick us back into runCandidate
r.logger.Warn("Election timeout reached, restarting election")
return
case <-r.shutdownCh:
return
}
}
}当执行Candidate逻辑时,首先构建了两个Channel:voteCh和prevoteCh,分别接受投票消息,和预投票消息(这里会根据是否开启了预投票这个Feature来判断是否要创建prevoteCh)。
prevote预投票阶段,在之前的Raft算法介绍中并没有提到。实际上这是一个优化,主要用于解决在出现网络分区时,少数派的节点由于无法选到Leader从而不停选举造成Term值不断增大,导致两个网络分区节点的Term值差距越来越大。而当网络恢复时,Leader就会因为Term值差距过大造成新一轮不必要的选举。加入预投票者一流程,就能在网络分区时,让少数派的节点无法进行选举,从而无法提升自己的Term值。
如果开启了预投票的Feature,则会调用r.preElectSelf()进入预投票阶段。预投票阶段会向所有有投票权的节点,发送PreVoteRequest请求,并将响应发送到一个Channel,最后返回这个Channel,用于后面的消息监听和处理。
如果不支持预投票的Feature,则直接进行投票阶段,执行r.electself()方法,和r.preElectSelf()方法十分类似,只是发送的请求是VoteRequest,同样也返回一个Channel。
接下来配置了一个electionTimer的Channel,将会在选举超时时得到消息。
接下来初始化了一些需要计算的值,比如preVote收到同意的节点数,vote收到同意的节点数,竞选Leader成功需要的票数等。然后开始for-select循环,对事件进行处理。核心的Channel主要是下面几个:
rpcCh:类似runFollower()方法,Candidate同样需要处理RPC请求。
prevoteCh:处理向其他节点发送preVoteRequest请求后得到的响应。并在大多数节点响应成功时,执行electSelf()方法真正执行选举。
voteCh:处理向其他节点发送voteRequest请求后得到的响应。并根据响应信息,判断当前Candidate是选举成功成为Leader,还是退回Follower。
electionTimer:判断是否选举超时,如果选举超时,需要退出重新执行runCandidate()方法,重新进行选举。
我们以voteCh的处理为例,分析下这段代码执行。其余的也都较为简单。
可以看到首先判断了得到的其他节点的响应中的Term值是否比本地Term值大,如果大则本地节点需要退回Follower角色并返回。否则继续执行,根据投票的响应判断是否得到了该节点的选票,如果得到了,则增加选票的计数。当判断出当前得到了大多数节点的投票时,就将自己转换为Leader,并返回。那么在run()方法的下一次循环中就会执行runLeader()方法,来执行Leader的逻辑。
runLeader()
// runLeader runs the main loop while in leader state. Do the setup here and drop into
// the leaderLoop for the hot loop.
func (r *Raft) runLeader() {
r.logger.Info("entering leader state", "leader", r)
metrics.IncrCounter([]string{"raft", "state", "leader"}, 1)
// Notify that we are the leader
overrideNotifyBool(r.leaderCh, true)
// Store the notify chan. It's not reloadable so shouldn't change before the
// defer below runs, but this makes sure we always notify the same chan if
// ever for both gaining and loosing leadership.
notify := r.config().NotifyCh
// Push to the notify channel if given
if notify != nil {
select {
case notify <- true:
case <-r.shutdownCh:
// make sure push to the notify channel ( if given )
select {
case notify <- true:
default:
}
}
}
// setup leader state. This is only supposed to be accessed within the
// leaderloop.
r.setupLeaderState()
// Run a background go-routine to emit metrics on log age
stopCh := make(chan struct{})
go emitLogStoreMetrics(r.logs, []string{"raft", "leader"}, oldestLogGaugeInterval, stopCh)
// Cleanup state on step down
defer func() {
close(stopCh)
// Since we were the leader previously, we update our
// last contact time when we step down, so that we are not
// reporting a last contact time from before we were the
// leader. Otherwise, to a client it would seem our data
// is extremely stale.
r.setLastContact()
// Stop replication
for _, p := range r.leaderState.replState {
close(p.stopCh)
}
// Respond to all inflight operations
for e := r.leaderState.inflight.Front(); e != nil; e = e.Next() {
e.Value.(*logFuture).respond(ErrLeadershipLost)
}
// Respond to any pending verify requests
for future := range r.leaderState.notify {
future.respond(ErrLeadershipLost)
}
// Clear all the state
r.leaderState.commitCh = nil
r.leaderState.commitment = nil
r.leaderState.inflight = nil
r.leaderState.replState = nil
r.leaderState.notify = nil
r.leaderState.stepDown = nil
// If we are stepping down for some reason, no known leader.
// We may have stepped down due to an RPC call, which would
// provide the leader, so we cannot always blank this out.
r.leaderLock.Lock()
if r.leaderAddr == r.localAddr && r.leaderID == r.localID {
r.leaderAddr = ""
r.leaderID = ""
}
r.leaderLock.Unlock()
// Notify that we are not the leader
overrideNotifyBool(r.leaderCh, false)
// Push to the notify channel if given
if notify != nil {
select {
case notify <- false:
case <-r.shutdownCh:
// On shutdown, make a best effort but do not block
select {
case notify <- false:
default:
}
}
}
}()
// Start a replication routine for each peer
r.startStopReplication()
// Dispatch a no-op log entry first. This gets this leader up to the latest
// possible commit index, even in the absence of client commands. This used
// to append a configuration entry instead of a noop. However, that permits
// an unbounded number of uncommitted configurations in the log. We now
// maintain that there exists at most one uncommitted configuration entry in
// any log, so we have to do proper no-ops here.
noop := &logFuture{log: Log{Type: LogNoop}}
r.dispatchLogs([]*logFuture{noop})
// Sit in the leader loop until we step down
r.leaderLoop()
}runLeader()方法中前面的大块内容都是用于测试相关的,注意到有一个双重select嵌套的方法,用于在收到终止信号时,依然要向notify这个Channel中丢一个true,也就实现了带有优先级的select语句,这个技巧也常在开源代码中见到。直到r.setupLeaderState()方法,开始初始化Leader角色的相关资源。然后调用emitLogStoreMetrics方法周期性的更新最早一条日志的时间这个监控指标,这里传入了一个stopCh,并在后面的defer调用的清理方法中关闭了stopCh,所以这里应用了关闭Channel时,所有监听Channel的协程都会收到Channel的数据类型的零值这个特点。
接下来定义了runLeader()方法退出时的清理动作。然后调用r.startStopReplication()方法,开启对各个节点的心跳和日志复制的协程。我们仔细看下这个replicate方法:
// replicate is a long running routine that replicates log entries to a single
// follower.
func (r *Raft) replicate(s *followerReplication) {
// Start an async heartbeating routing
stopHeartbeat := make(chan struct{})
defer close(stopHeartbeat)
r.goFunc(func() { r.heartbeat(s, stopHeartbeat) })
RPC:
shouldStop := false
for !shouldStop {
select {
case maxIndex := <-s.stopCh:
// Make a best effort to replicate up to this index
if maxIndex > 0 {
r.replicateTo(s, maxIndex)
}
return
case deferErr := <-s.triggerDeferErrorCh:
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
if !shouldStop {
deferErr.respond(nil)
} else {
deferErr.respond(fmt.Errorf("replication failed"))
}
case <-s.triggerCh:
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
// This is _not_ our heartbeat mechanism but is to ensure
// followers quickly learn the leader's commit index when
// raft commits stop flowing naturally. The actual heartbeats
// can't do this to keep them unblocked by disk IO on the
// follower. See https://github.com/hashicorp/raft/issues/282.
case <-randomTimeout(r.config().CommitTimeout):
lastLogIdx, _ := r.getLastLog()
shouldStop = r.replicateTo(s, lastLogIdx)
}
// If things looks healthy, switch to pipeline mode
if !shouldStop && s.allowPipeline {
goto PIPELINE
}
}
return
PIPELINE:
// Disable until re-enabled
s.allowPipeline = false
// Replicates using a pipeline for high performance. This method
// is not able to gracefully recover from errors, and so we fall back
// to standard mode on failure.
if err := r.pipelineReplicate(s); err != nil {
if err != ErrPipelineReplicationNotSupported {
s.peerLock.RLock()
peer := s.peer
s.peerLock.RUnlock()
r.logger.Error("failed to start pipeline replication to", "peer", peer, "error", err)
}
}
goto RPC
}可以看到首先是创建心跳协程,调用的r.heartbeat方法,用心跳超时时间的十分之一作为定时的间隔,或者等待notifyCh收到通知时,向Follower发送空的AppendEntries请求。
然后我们看到有两个用标签标记点,分别是RPC和PIPELINE,代表着两种日志复制的方式,即增量的逐条复制,和批量的复制。首先会尝试进行逐条的复制方式,当有新日志需要被复制时,会从s.triggerCh接收到通知,然后调用r.replicateTo,接收最新一条日志项的索引,进行日志复制。当顺利完成一次日志项的复制时,通过goto PIPELINE的方式,进入到批量复制的模式以提高效率,调用的是r.pipelineReplicate方法,该方法会持续运行,直到批量复制出现错误时,再通过goto RPC回到逐条复制的模式。
接下来我们回到runLeader()方法,在启动了心跳和日志复制的协程后,会执行r.dispatchLogs方法,并传入一个no-op的空日志项,r.dispatchLogs方法会调用LogStore组件的StoreLogs方法将日志项写入磁盘。并通知日志复制协程对复制该日志。通过调度无操作日志条目,确保当前领导者的提交索引能够尽可能更新到最新的提交状态,即使在没有客户端命令的情况下。最后一步就是执行r.leaderloop()方法,执行leader对各种通知进行处理的逻辑,类似Follower和Candidate,这里同样是通过for-select循环,通过Channel处理各种事件。
Follower处理日志复制
Leader会通过向Follower发送AppendEntries的RPC请求进行日志复制,当Folower接收到请求时会通过注册的Transport模块将RPC请求送入rpcCh中,然后根据我们前文我们对runFollower()方法的分析,rpcCh中的请求会被取出,执行r.processRPC方法并分发到AppendEntries的处理逻辑中,最终执行的是LogStore模块的StoreLogs方法,完成日志的持久化。然后会执行r.processLogs方法,将日志项提交给fsmMutateCh这个Channel中,由runFSM方法完成日志项提交给有限状态机执行。
分析完核心处理逻辑run方法后,我们再进行分析另一个重要的协程,处理提交有限状态机的runFSM方法。
runFSM方法
// runFSM is a long running goroutine responsible for applying logs
// to the FSM. This is done async of other logs since we don't want
// the FSM to block our internal operations.
func (r *Raft) runFSM() {
var lastIndex, lastTerm uint64
batchingFSM, batchingEnabled := r.fsm.(BatchingFSM)
configStore, configStoreEnabled := r.fsm.(ConfigurationStore)
applySingle := func(req *commitTuple) {
// Apply the log if a command or config change
var resp interface{}
// Make sure we send a response
defer func() {
// Invoke the future if given
if req.future != nil {
req.future.response = resp
req.future.respond(nil)
}
}()
switch req.log.Type {
case LogCommand:
start := time.Now()
resp = r.fsm.Apply(req.log)
metrics.MeasureSince([]string{"raft", "fsm", "apply"}, start)
case LogConfiguration:
if !configStoreEnabled {
// Return early to avoid incrementing the index and term for
// an unimplemented operation.
return
}
start := time.Now()
configStore.StoreConfiguration(req.log.Index, DecodeConfiguration(req.log.Data))
metrics.MeasureSince([]string{"raft", "fsm", "store_config"}, start)
}
// Update the indexes
lastIndex = req.log.Index
lastTerm = req.log.Term
}
applyBatch := func(reqs []*commitTuple) {
if !batchingEnabled {
for _, ct := range reqs {
applySingle(ct)
}
return
}
// Only send LogCommand and LogConfiguration log types. LogBarrier types
// will not be sent to the FSM.
shouldSend := func(l *Log) bool {
switch l.Type {
case LogCommand, LogConfiguration:
return true
}
return false
}
var lastBatchIndex, lastBatchTerm uint64
sendLogs := make([]*Log, 0, len(reqs))
for _, req := range reqs {
if shouldSend(req.log) {
sendLogs = append(sendLogs, req.log)
}
lastBatchIndex = req.log.Index
lastBatchTerm = req.log.Term
}
var responses []interface{}
if len(sendLogs) > 0 {
start := time.Now()
responses = batchingFSM.ApplyBatch(sendLogs)
metrics.MeasureSince([]string{"raft", "fsm", "applyBatch"}, start)
metrics.AddSample([]string{"raft", "fsm", "applyBatchNum"}, float32(len(reqs)))
// Ensure we get the expected responses
if len(sendLogs) != len(responses) {
panic("invalid number of responses")
}
}
// Update the indexes
lastIndex = lastBatchIndex
lastTerm = lastBatchTerm
var i int
for _, req := range reqs {
var resp interface{}
// If the log was sent to the FSM, retrieve the response.
if shouldSend(req.log) {
resp = responses[i]
i++
}
if req.future != nil {
req.future.response = resp
req.future.respond(nil)
}
}
}
restore := func(req *restoreFuture) {
// Open the snapshot
meta, source, err := r.snapshots.Open(req.ID)
if err != nil {
req.respond(fmt.Errorf("failed to open snapshot %v: %v", req.ID, err))
return
}
defer source.Close()
snapLogger := r.logger.With(
"id", req.ID,
"last-index", meta.Index,
"last-term", meta.Term,
"size-in-bytes", meta.Size,
)
// Attempt to restore
if err := fsmRestoreAndMeasure(snapLogger, r.fsm, source, meta.Size); err != nil {
req.respond(fmt.Errorf("failed to restore snapshot %v: %v", req.ID, err))
return
}
// Update the last index and term
lastIndex = meta.Index
lastTerm = meta.Term
req.respond(nil)
}
snapshot := func(req *reqSnapshotFuture) {
// Is there something to snapshot?
if lastIndex == 0 {
req.respond(ErrNothingNewToSnapshot)
return
}
// Start a snapshot
start := time.Now()
snap, err := r.fsm.Snapshot()
metrics.MeasureSince([]string{"raft", "fsm", "snapshot"}, start)
// Respond to the request
req.index = lastIndex
req.term = lastTerm
req.snapshot = snap
req.respond(err)
}
saturation := newSaturationMetric([]string{"raft", "thread", "fsm", "saturation"}, 1*time.Second)
for {
saturation.sleeping()
select {
case ptr := <-r.fsmMutateCh:
saturation.working()
switch req := ptr.(type) {
case []*commitTuple:
applyBatch(req)
case *restoreFuture:
restore(req)
default:
panic(fmt.Errorf("bad type passed to fsmMutateCh: %#v", ptr))
}
case req := <-r.fsmSnapshotCh:
saturation.working()
snapshot(req)
case <-r.shutdownCh:
return
}
}
}通过注释可以知道该方法主要是将日志提交给FSM(即执行FSM的Apply方法)。首先可以看到这里定义了几个方法:applySingle、applyBatch、restore、snapshot分别用于提交单条日志项、批量提交日志项、从快照中恢复FSM,和生成当前FSM的快照。
接下来进入runFSM方法的主体逻辑,也是一个for-select代码块,逻辑比较简单,就是监听fsmMutateCh和fsmSnapshotCh的通知,然后根据不同类型的通知,执行上述预定义的几个方法。完成对应的状态机的操作。根据我们上面分析run方法的过程可与你知道,这些都是由run方法执行过程中的特定时机触发的。
runSnapshot方法
最后我们看下runSnapshot方法,该方法主要是通知FSM生成快照,使用FSM生成的快照调用SnapshotStore模块的Create方法创建快照,通过调用r.takeSnapshot()方法完成,可以定时触发或者由用户主动触发。代码逻辑比较简单,如下:
// runSnapshots is a long running goroutine used to manage taking
// new snapshots of the FSM. It runs in parallel to the FSM and
// main goroutines, so that snapshots do not block normal operation.
func (r *Raft) runSnapshots() {
for {
select {
case <-randomTimeout(r.config().SnapshotInterval):
// Check if we should snapshot
if !r.shouldSnapshot() {
continue
}
// Trigger a snapshot
if _, err := r.takeSnapshot(); err != nil {
r.logger.Error("failed to take snapshot", "error", err)
}
case future := <-r.userSnapshotCh:
// User-triggered, run immediately
id, err := r.takeSnapshot()
if err != nil {
r.logger.Error("failed to take snapshot", "error", err)
} else {
future.opener = func() (*SnapshotMeta, io.ReadCloser, error) {
return r.snapshots.Open(id)
}
}
future.respond(err)
case <-r.shutdownCh:
return
}
}
}总结
上面我们分析了Hashicorp Raft的主体逻辑和各个模块的作用,整体来说逻辑很流畅,注释也很清晰。其中也用到了比如带有优先级的select、加锁的优化、通过关闭Channel通知同时多个协程等技巧,还是很值得学习的。如下为根据大体上的逻辑整理的一张草图:
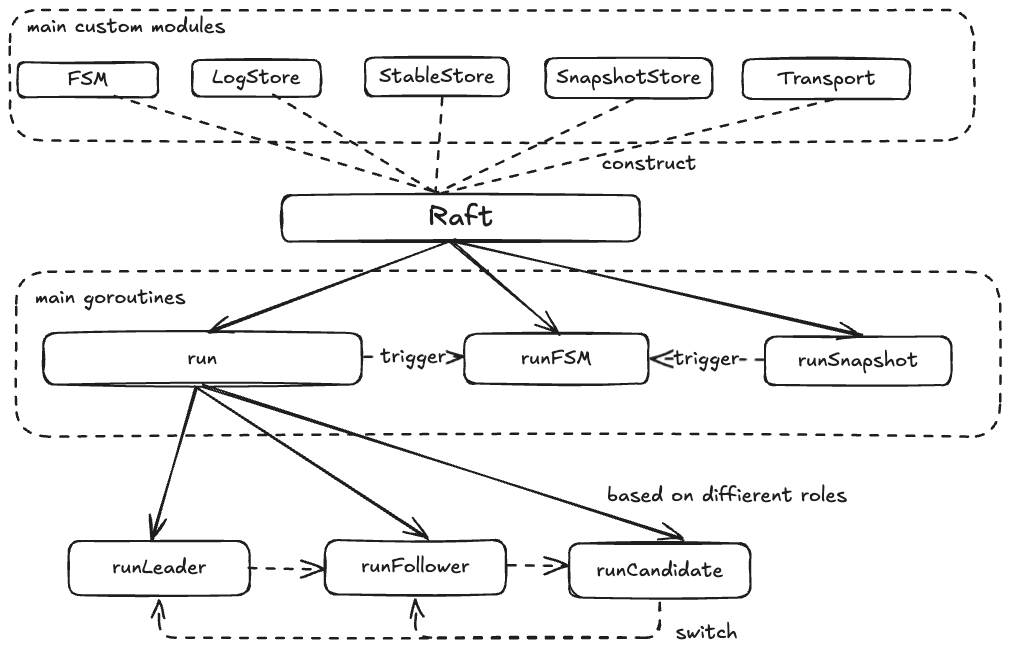
接下来我们基于Hashicorp Raft,来实现一个自己的分布式KV系统,增强对Raft算法的在实际应用中的理解。
评论区