


架构
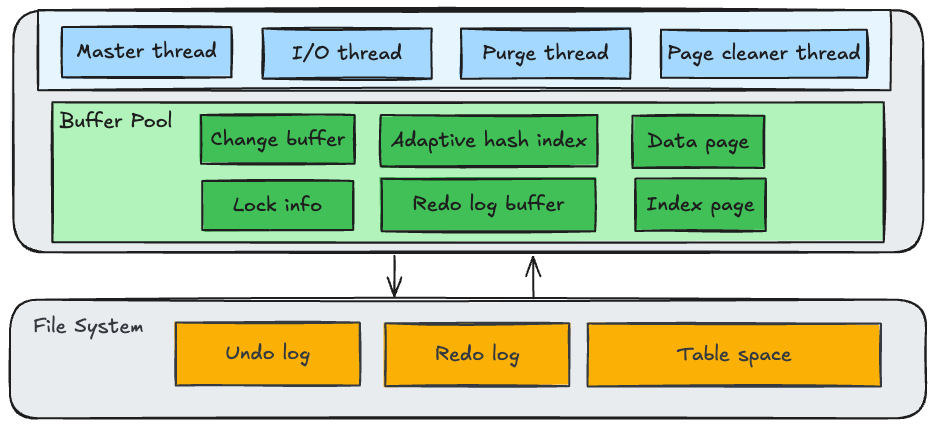
InnoDB存储引擎的体系架构大致如上图所示,可以看到主要包含了一系列后台线程,和一个大的缓冲池,里面包含了一些不同功能的Buffer。最底层则是文件系统的一些空间和日志。
线程模型
如上图所示,InnoDB的线程主要分为Master线程、IO线程、Purge线程和Page Cleaner线程。
Master线程
Master线程是核心的后台线程,主要负责调度其他线程,以及脏页的刷新,undo页的回收,redo log的刷新,合并缓冲区等(不同版本做的工作不尽相同)。
I/O线程
Innodb中大量使用了AIO(异步IO)来处理写请求,以提高性能,IO线程则用于处理这些IO操作的回调。
通过show engine innodb status命令可以查看到InnoDB存储引擎内部的一些状态信息,当前各个IO线程的状态,也可以看到:
mysql> show engine innodb status\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2024-10-25 23:17:40 0x16f51b000 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 2 seconds
......
--------
FILE I/O
--------
I/O thread 0 state: waiting for i/o request (insert buffer thread)
I/O thread 1 state: waiting for i/o request (read thread)
I/O thread 2 state: waiting for i/o request (read thread)
I/O thread 3 state: waiting for i/o request (read thread)
I/O thread 4 state: waiting for i/o request (read thread)
I/O thread 5 state: waiting for i/o request (write thread)
I/O thread 6 state: waiting for i/o request (write thread)
I/O thread 7 state: waiting for i/o request (write thread)
I/O thread 8 state: waiting for i/o request (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:
Pending flushes (fsync) log: 0; buffer pool: 0
1742 OS file reads, 423 OS file writes, 116 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
......
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.00 sec)可以看到所有的I/O线程的功能,以及当前状态。
Purge线程
事务提交后,这个事务的undo log可能需要进行回收(能不能回收要看还有没有事务需要用到相关undo log的版本链,实际上只有update undo log需要被回收,Insert undo log在事务结束后就可以删除了)。
在InnoDB1.1版本可以通过在配置文件上加上这行开启,并且值只能设为1:
[mysqld]
innodb_purge_threads=1 InnoDB 1.2版本以后可以支持多个purge thread,加快undo log的回收:
mysql> show variables like 'innodb_purge_threads';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_purge_threads | 1 |
+----------------------+-------+
1 row in set (0.00 sec)Page Cleaner线程
在Innodb1.2版本引入,用于将脏页刷新的操作都放到这个线程完成,调用IO线程的write线程完成刷盘处理,减轻master线程对于用户查询的阻塞。
Buffer Pool
InnoDB使用一个大的缓冲池,来解决内存和磁盘读写的访问速度鸿沟。buffer pool的主要作用,就是作为磁盘的缓冲。当读数据时,如果数据所在的页在缓冲池,则直接从缓冲池读取并返回;当写入数据时,如果该数据所在的页在缓冲池,则先修改缓冲池中的数据页并返回,后续在一定时机统一将缓冲池中的数据页统一刷到磁盘。
通过参数innodb_buffer_pool_size可以设置buffer pool的大小。
mysql> show variables like "innodb_buffer_pool_size";
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.00 sec)从Innodb1.0开始,可以通过参数Innodb_buffer_pool_instances设置多个缓冲池,然后各个数据页可以均匀分配到多个缓冲池中,提高并发效率。
mysql> show variables like "innodb_buffer_pool_instances";
+------------------------------+-------+
| Variable_name | Value |
+------------------------------+-------+
| innodb_buffer_pool_instances | 1 |
+------------------------------+-------+
1 row in set (0.01 sec)如上面的图中所示,Buffer Pool中会包含很多块内存区域,用来缓存不同的数据。核心包含以下几块
Data Page:数据页,缓存B+树的数据页
Index Page:索引页, 缓存B+树的索引页
Change Buffer:修改缓冲区
Adaptive Hash Index:自适应哈希索引
Redo Log Buffer:重做日志的缓存
接下来我们将通过buffer pool的管理方式了解这些块的作用和运作方式。
Redo log buffer
Redo log是InnoDB用于崩溃恢复的日志。他会包含两部分,一部分在内存中,一部分在磁盘上,大小相同。在事务中每次写入redo log实际上也是先写入redo log buffer,然后根据redo log的刷盘策略将redo log刷到磁盘。通过参数innodb_flush_log_at_trx_commit设置,它有0、1、2三个可选参数:
0:延迟写:每次事务提交先写到Redo log buffer,然后每隔1s将Redo log写入os buffer,并立刻调用
fsync()刷到磁盘,这样如果系统崩溃的话最多会丢失1s的数据。1:实时写,每次事务提交,立刻刷到磁盘,这种方式不会丢数据,但是因为每次都访问磁盘,所以性能稍差,但是由于redo log的写入是顺序的,相比与内存的随机IO可能还差不多,为了安全起见,大部分时候还是设为1的。
2:实时写,延迟刷,每次提交事务,都先写到redo log buffer,并写到os buffer,然后间隔1s调用
fsync()刷到磁盘,这种是个折中的方案。和0的差别是如果MySQL进程挂了但是机器没挂可以保证不丢数据,如果机器挂了,那么也最多会丢失1s的数据。
Redo log buffer的大小和已通过参数innodb_log_buffer_size设置,默认是8M,这个参数需要设置一个合理的值,太小就会频繁的满然后频繁的触发checkpoint,太大会让MySQL重启时数据恢复时间变长。
mysql> show variables like "innodb_log_buffer_size";
+------------------------+----------+
| Variable_name | Value |
+------------------------+----------+
| innodb_log_buffer_size | 67108864 |
+------------------------+----------+
1 row in set (0.01 sec)Redo Log的工作机制可以查看这篇文章。
数据页和索引页
LRU
这部分存储的就是磁盘中的实际表数据,InnoDB的表是通过聚簇索引以B+树形式存储的。所以buffer pool中存的数据页和索引页也是一个个的B+树,InnoDB的一个页的大小默认是16kb,数据页和索引页在buffer pool中通过LRU算法(最近最少访问)进行管理。通过一个链表把数据页和索引页串起来,最近使用的页就插入到LRU链表的前端,当数据页和索引页占用的空间大小超过了缓冲池大小时,LRU链表的尾部的数据页会被淘汰掉。
InnoDB对传统的LRU算法进行了优化,新页会被插到LRU链表的中间的midpoint位置(大概5/8处),而不是最前端。这实际上是为了防止真正的热点数据被新加入LRU的数据挤出队列。比如当批量查询数据时,需要访问表中的许多页甚至全部页,而这些页可能只用这一次,这大量的页如果占据了LRU链表当前最前端的页,就会导致原本被频繁访问的LRU的头部的页被刷出,后续再访问这些真正热点的页时就得访问磁盘冷读,性能就会很差。
插入的midpoint的位置可以通过参数innodb_old_blocks_pct设置,默认是37,即后面37%的位置。如果预估热点数据可能很多,也可以尽量调小这个值。
mysql> show variables like "innodb_old_blocks_pct";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_old_blocks_pct | 37 |
+-----------------------+-------+
1 row in set (0.00 sec)还有另一个可调整的参数用于LRU优化,innodb_old_blocks_time,用于表示页读取到mid位置后需要等待多久才会被加入到LRU列表的热端,默认是1000,也就是通过命令set global innodb_old_blocks_time=0;设置永远不移到前面,以防止真正的热点数据后续还是会被刷出队列。
mysql> show variables like "innodb_old_blocks_time";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_old_blocks_time | 1000 |
+------------------------+-------+
1 row in set (0.01 sec)除此之外,innodb1.0版本开始支持压缩页的功能,原本16kb的页可以压缩到几kb,非16kb的页是通过unzip_LRU列表进行管理的,命令show engine innodb status\G可以看到。
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 0
Dictionary memory allocated 721910
Buffer pool size 8191
Free buffers 6326
Database pages 1865
Old database pages 707
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 1719, created 146, written 214
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1865, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]脏页的刷盘时机
Buffer pool中LRU链表上的数据页和索引页,如果被修改了的话,这个页就被称为脏页,即Buffer pool中的数据,和磁盘上存储的数据产生了不一致。脏页会被InnoDB保存到Flush链表,然后在一定时机通过Checkpoint机制将脏页刷到磁盘。通过show engine innodb status\G可以看到当前的脏页数量。显示在Modified db pages 字段。
Flush列表
即脏页列表,LRU链表中被修改的页会拷贝一份到FLush列表,即脏页同时存在于LRU列表和Flush列表中,两个列表的功能不一样,互不影响。
Checkpoint刷盘机制
除了Page Cleaner或者Master线程会以1s或者10s一次定期的将Flush列表中的脏页刷盘,还有几种情况下会触发checkpoint机制进行脏页刷盘,比如redo log满了,LRU链表满了等。
Redo log满了
Redo log是大小固定的文件,用于MySQL宕机时的灾难恢复,可以保证MySQL宕机重启时不会丢数据。redo log可以理解为一个环形的文件,当redo log写满时需要擦除redo log前面的内容才能继续写,此时就需要进行checkpoint刷盘。
LRU链表满了
当LRU链表中尾部需要被淘汰的数据页是脏页时,就要强制触发Checkpoint刷盘。LRU链表一般需要保证有100个左右的空闲页可用,当空间不足时,就会从列表尾端淘汰一些。
脏页数量太多
参数innodb_max_dirty_pages_pct可以控制这个阈值,当超过这个阈值时,就会触发刷盘操作。
mysql> show variables like "innodb_max_dirty_pages_pct";
+----------------------------+-----------+
| Variable_name | Value |
+----------------------------+-----------+
| innodb_max_dirty_pages_pct | 90.000000 |
+----------------------------+-----------+
1 row in set (0.01 sec)脏页刷盘的策略则有两种,分别是Sharp checkpoint,将所有脏页刷到磁盘。发生在数据库关闭时;和Fuzzy checkpoint,只刷部分脏页到磁盘。大多数时候都是Fuzzy Checkpoint。
刷新邻接页
当某些场景触发了checkpoint,需要刷脏页时,InnoDB会自动检测该页所在区的所有页,如果也是脏页,那么就会一起刷了,多个脏页的刷新合并成一个IO操作,以提高效率,对机械磁盘比较有效。
但是刷新邻接页也存在问题:
邻接页可能是一个不食特别脏的页,刷了这个页后该页又很快变成了脏页。
固态硬盘SSD有较高的IOPS(每秒输入输出量),可能并不需要这个功能。
针对以上问题,从1.2版本开始提供参数innodb_flush_neighbors,可以选择开启或者不开启这个特性,最新版本默认是不开启状态。
mysql> show variables like "innodb_flush_neighbors";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_flush_neighbors | 0 |
+------------------------+-------+
1 row in set (0.00 sec)Double Write问题
Buffer pool中的脏页在触发checkpoint刷新到磁盘时,都是以页为单位刷的,一个页是16kb,而文件系统是以4kb为单位写入的,机械磁盘是以扇区(512字节)为单位写入的,这就导致16kb的脏页被刷到磁盘上不是一个原子操作。可能会发生宕机时,一个页只有4kb写入了磁盘,剩下的没写入。
Redo log的写入单位和磁盘的扇区大小一样是512字节,所以redo log的写入是原子的,不会产生坏页。脏页刷盘时如果一个页没刷完,理论上是可以通过Redo log的Checkpoint点来继续刷的,但是由于redo log是物理逻辑日志,不是纯物理日志,所以不能用redo log进行恢复。
Note:
物理日志: 记录的是一个页中发生改变的字节,这样重复多次执行也不会导致数据不一致,它是幂等的,但是日志量会比较大 逻辑日志:像binlog,记录的就是一条条操作语句,它不是幂等的,但是日志量比物理日志小的多 物理逻辑日志:redo log,对应的页是物理的,但是页内部的操作是逻辑的,物理逻辑日志不是完全幂等的, 如果页本身发生了损坏,那用redo log是恢复不了的。
部分写问题的解决方式:当一个页发生部分写失败时,需要还原这个页到之前的状态,再通过redo log进行重做。两次写就是InnoDB解决这个问题的方式。
两次写
通过增加了一个Double write buffer。维护一个占用2Mb的Double write buffer在内存空间和磁盘上的共享表空间ibdata,128个页,120个页用于批量刷新脏页,8个页用于单页刷新。
刷脏页时double write的执行过程为:
先通过memcpy函数将脏页复制到内存的double write buffer。
之后double write会分两次,每次1Mb的顺序的把页写入磁盘上的ibdata文件,这个过程是直接调用fsync函数立刻写入磁盘的。因为是顺序写,所以开销并不是很大。
完成磁盘上的double write写入后,最后再把double write buffer中的脏页写入磁盘上的各个表空间文件。
通过命令show global status like "innodb_dblwr%";可以观察double write的运行情况:如下一共写了73个页,写的次数是7。
mysql> show global status like "innodb_dblwr%";
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Innodb_dblwr_pages_written | 73 |
| Innodb_dblwr_writes | 7 |
+----------------------------+-------+
2 rows in set (0.01 sec)刷脏页时MySQL崩溃的恢复过程
InnoDB会先去共享表空间找到double write中该页的副本;
如果该副本不完整,则说明上次刷盘时,double write写入磁盘时就失败了,还没到后面真正刷脏页的过程,真正的数据页没有写了一部分污染,它是完整的,那么就可以丢弃这个副本,直接用Redo log恢复即可。
如果副本完整,则说明上次刷盘时,已经过了double write写磁盘的阶段,表空间中页就有可能是不完整的(当然,也有可能是完整的),不管它完不完整都可以通过完整的Double write副本直接恢复这个页,然后再应用Redo log看看需不需要恢复即可(Redo log可以和double write中的数据副本对应上的,看看一不一致,不一致就用Redo log恢复,一致就跳过即可)。
Change Buffer
Change buffer或者是以前的Insert buffer,是为了优化二级索引(非唯一)刷盘时的插入效率,它也存在Buffer pool,并且会持久化。通过show engine innodb status\G;可以查看到相关信息:
mysql> show engine innodb status\G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
......
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
......刷盘时二级索引的插入问题
当插入一个新行时,如果这个行要插入的页不在Buffer pool,就需要先把这个页从磁盘取出来。对于主键索引,由于它一般都是递增的,所以直接从磁盘取出最后一个页,把新插入的行往B+树的最后按顺序加即可。而对于二级索引来说,新加的这行的索引字段往往不是最后面的,不能顺序插入,就需要随机IO磁盘,拿到这行数据应该插入的页,然后保存这个页到Buffer pool,然后插入到Buffer pool中这个页的B+树上,这里就有随机的磁盘IO了,导致效率较低。Insert Buffer/Change Buffer就是为了解决加载二级索引时磁盘随机IO效率低的问题,Insert buffer / Change buffer同样既存在Buffer pool中,也存在磁盘上,重启后可以从磁盘中加载回来。
Change buffer是一棵B+树,在MySQL 4.1版本前是一张表有一棵,存储的是这张表的所有二级索引,后续改为了全局只有一颗B+树,负责所有的二级索引。
使用要求和过程
Change Buffer的使用要求
索引不是聚簇索引,因为聚簇索引不需要优化。
索引不是唯一索引,因为要保证唯一的话,要去遍历二级索引判断是否重复,无论怎样都要遍历,优化没意义。
Change Buffer的使用过程:
当有一行数据要插入/更新到某个表时,数据需要插入到这个表的主键索引和所有二级索引上,首先检查这行数据要写入的页在不在buffer pool的LRU链表上。
如果主键索引页和二级索引页都在LRU链表上,则可以直接操作内存直接更新。
如果主键索引不在LRU链表上,则直接顺序IO磁盘,拿到主键索引的最后一个数据页放到LRU链表,然后插入即可
如果二级索引页不在LRU链表上,则把这个插入操作先放到insert buffer中。(insert buffer在事务提交后也会持久化到共享表空间的ibdata文件,并且也会写入redo log中),并不去随机IO磁盘,然后之后根据一定频率和情况进行merge,merge的过程就是InnoDB再进行随机磁盘IO,把这个二级索引的数据页从磁盘加载到buffer pool的LRU链表上,然后再把insert buffer和buffer pool中的这个页进行merge操作,同时这个页变成脏页。
Merge发生的时机
如果change buffer中的记录操作的二级索引页刚好被从磁盘读入buffer pool。
Change buffer的空间用光了,不能再写了,必须先从磁盘随机IO取出二级索引页先进行merge,给change buffer腾出空间。
Master线程会周期性的进行merge。
Change Buffer的问题
在写频繁的情况,如果Buffer pool中没有需要操作的二级索引页,就都需要写Insert buffer,导致Insert buffer过大,占了Buffer pool的大部分。(MySQL 5.5之前的叫做Insert buffer,InnoDB 1.0Z 版本后改为Change buffer,顾名思义,不仅是插入,修改和删除操作也做了优化),1.2版本开始可以通过参数innodb_change_buffer_max_size来控制change buffer的最大使用内存,最大值是50,默认是25,表示最多是25%的buffer pool的空间。
如果MySQL某时刻宕机了,就可能磁盘中真实存储的二级索引页还没和insert buffer合并,这时用ibd文件恢复的话会不成功,需要进行Repair table来重建表的二级索引。
因为merge的时候是真正进行数据更新的时刻,而Change buffer的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做merge之前,Change buffer记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时Change buffer的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在Change buffer,但之后由于马上要访问这个数据页,会立即触发merge过程。这样随机访问I/O的次数不会减少,反而增加了Change buffer的维护代价。
和Redo log的区别
Redo log优化的是向磁盘随机写的操作(改为顺序写),而Change buffer解决的是从磁盘随机读二级索引的问题(先记录,后merge)。
总体而言redo log和change buffer的执行顺序是:、
当执行写入操作时,如果要操作的页在内存中,就直接更新内存即可。
如果页不在内存,则需要从磁盘加载这个页,如果要加载的页是二级索引的页,则可以使用Change buffer先记录下来这次修改。如果是唯一索引,则不能使用change buffer,只能老老实实的加载数据页到内存,然后遍历检查唯一约束。
然后就可以将上述操作记录在Redo log中(如果用了Change buffer,那么在Redo log中也会有记录)。
然后就是Redo log的两阶段提交了。
自适应哈希索引
Buffer pool中还包含了一块叫做自适应哈希索引的区域。故名思义,就是存储哈希索引。哈希索引在等值查询时,改用hashmap提高B+树的访问速度。通过参数innodb_adaptive_hash_index设置是否开启,默认都是开启状态。
MySQL中只有memory引擎支持和哈希索引,innodb是自己加了个自适应的哈希索引。
哈希索引的创建规则是:相同的查询,并且都是等值查询的情况使用索引访问了17次,相同模式的查找访问了超过了100次,这个数据就会成为一个热点数据,那么就会给这个查询建立一个哈希索引,下一次的相同查询可以直接从哈希索引中取得,就不用再去Buffer pool中去查找和访问磁盘上的数据页了。
参考
[1] 《高性能MySQL》
[2] 《MySQL技术内幕:InnoDB存储引擎》
评论区