MySQL的架构和语句执行过程
MySQL的整体架构图
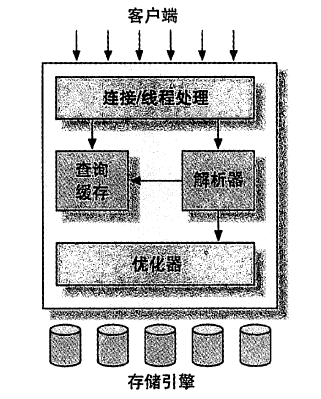
如上图所示,整体上看MySQL分成上下两层,上面那层是Server层,下面是存储引擎层。
Server层包含了连接器、查询缓存、解析器、优化器、执行器(有的资料中说有)等组件,,主要负责的是跨存储引擎的功能,如存储过程、触发器、视图等,内置函数也是在Server层提供的。
存储引擎层则是MyISAM、InnoDB、Memory等各种存储引擎,以插件式集成,负责数据的读写。
连接器
用于和客户端建立连接,并维持和管理连接。并在连接建立时查询用户的权限表获取到该用户的所有权限,建立连接的过程大概如下:
- 首先进行TCP握手,建立TCP连接
- 然后进行身份认证,这一步会查询MySQL的权限表,通过后会从权限表中拿到用户的所有权限,并保存在这个连接中,后续的所有权限判断,都是基于这次查询得到的权限数据,不会再去查权限表了
- 通过用户的身份认证之后,连接就建立起来了
通过命令show processlist可以观察当前数据库的所有连接:
Mysql> show processlist;
+----+-------------+-----------------------------------------+-----------+-------------+------+-----------------------------------------------------------------------+------------------+----------+
| Id | User | Host | db | Command | Time | State | Info | Progress |
+----+-------------+-----------------------------------------+-----------+-------------+------+-----------------------------------------------------------------------+------------------+----------+
| 2 | system user | | NULL | Daemon | NULL | InnoDB purge coordinator | NULL | 0.000 |
| 1 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 |
| 3 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 |
| 4 | system user | | NULL | Daemon | NULL | InnoDB purge worker | NULL | 0.000 |
| 5 | system user | | NULL | Daemon | NULL | InnoDB shutdown handler | NULL | 0.000 |
| 82 | root | localhost | employees | Query | 0 | Init | show processlist | 0.000 |
| 83 | replica | test:48936 | NULL | Binlog Dump | 2265 | Master has sent all binlog to slave; waiting for binlog to be updated | NULL | 0.000 |
+----+-------------+-----------------------------------------+-----------+-------------+------+-----------------------------------------------------------------------+------------------+----------+
7 rows in set (0.000 sec)
可以看到当前有几个daemon的daemonset线程,还有个本地的Query查询,还有一个复制的线程在工作。
当客户端太久没有操作,连接器会自动断开,超时时间由参数wait_timeout控制,默认是8小时,28800秒。
Mysql> show variables like "wait_timeout";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set (0.001 sec
使用MySQL建立连接时要注意的问题:
大量的短连接可以改成长连接
如果每次都进行很少的操作就断开连接,下次查询时再重新建立连接的话,多了很多不必要的资源浪费,尽量使用长连接,并在多个查询中复用这个连接。或者使用连接池,要访问MySQL就去连接池里拿一个连接回来。
大量的长连接会造成问题
如果有大量的长连接,那么连接过程中所执行的一些操作都会保存在连接器的连接对象里,会占用很多内存资源,严重时甚至会OOM。如果长连接太多,并且观察到数据库的内存占用超过了阈值,那么要么扩大内存,或者对长连接定期的断开,再重连。对于MySQL5.7以上的版本,可以在进行了一个大的操作后,使用命令mysql_reset_connection来初始化连接资源,这并不会让这个连接断开,只是清理了连接对象的一些资源。
查询缓存
如果开启了查询缓存,那么在建立了连接后,会先到查询缓存中查找,看能否命中。查询缓存中存储的是key-value形式的数据,key就是查询类型的SQL语句的哈希值,value就是结果集,和操作的所有表的信息。
如果命中了查询缓存,则会检查连接时获取到的用户的权限,和查询缓存中记录的访问的所有表进行对比,确认用户拥有访问这些表的权限后,就可以直接把结果集返回给用户。
如果没有命中,就需要继续向后走分析器、优化器,直到从存储引擎中得到数据集返回给用户,再返回之前,这个结果集也会保存一份到查询缓存中,用户后续如果有相同的查询,则可以命中。
查询缓存的问题
-
只要有一个表有更新,那么这个表涉及的查询缓存都会被清空,所以对于更新频繁的表,查询缓存命中率非常的低,除非是那种几乎不会变,但是又经常要被查询的表才有用。
这种情况其实可以设置
query_cache_type=DEMAND,这样对于所有查询语句,默认都不生成查询缓存,如果有确定需要使用查询缓存的语句,可以通过SQL_CACHE显式的指定就可以了,如:mysql> select SQL_CACHE * from T where ID=10;// 生成查询缓存 -
查询语句不同,即使结果集相同,也不会命中查询缓存,反而会在查询缓存中保存两份相同的结果集。
-
hash计算,哈希查找,哈希碰撞都会带来额外的性能消耗,如果还没命中,还就更得不偿失了。
因为以上的问题,MySQL8.0把查询缓存整个模块都删了。
分析器
分析器作用就是解析SQL语句,将SQL语句转换为MySQL可以执行的函数。
分析器分成词法分析,和语法分析两部分:
-
词法分析,会识别出SQL语句的各个字符串是什么,代表什么,然后生成一颗解析树。不管你SQL写的对不对,最终都能生成一颗解析树,所以在词法分析阶段是不会报错的。
-
语法分析:对解析树进行判断,判断是否满足MySQL的语法,这里会访问表结构,检查表名、字段名等是否正确,如果有错误就会报错给客户端。
分析器执行之后会有一次权限验证,叫做precheck,因为这一步已经知道这个SQL要访问的是哪个database、哪个table了,所以可以进行一次预检查,依然是通过刚刚建立连接时保存的用户权限信息,进行检查,如果权限没问题,则会进行下一步。否则就会返回权限错误。
优化器
经过分析器后,MySQL已经知道要做什么了,优化器的作用是对操作进行优化。
比如,如果要访问的表里有多个索引,那么使用哪个索引最优,就是优化器要考虑的。再比如,多表join时,先查哪个表,再根据外键字段查哪个表,这也是优化器需要做的。
执行器
有的资料上没有写这个模块,比如本文一开始的那张图,出自《高性能MySQL》。不管有没有这个模块,这部分要做的事非常简单。
首先在执行器的一开始,会做最后一次的权限校验,如果权限不够则会返回错误。
权限认证通过后,则会调用存储引擎对应的接口拿到数据或完成操作,根据操作类型不同,可能会再对数据做一些处理,然后返回给客户端。
为什么执行器还要做权限检查?
在分析器的最后可以确认与SQL语句本身相关的表有哪些,可以确认用户对这些表是否有相关操作权限,但是还有些其他的操作可能在SQL语句中并未体现,比如如果有个触发器,必须在执行阶段,才能知道,所以只有在执行器阶段才能做最终的权限校验。
把权限的检查分解到多个步骤,也是为了提高效率,在某些权限不满足时不用到了执行器就可以直接返回。
整个的认证过程:
- 在连接器阶段,进行认证,并获取用户权限,并不做权限校验
- 在命中查询缓存时,根据查询缓存中保存的表信息,进行权限的检查
- 在分析器阶段,确认了SQL语句本身要操作的表信息,进行权限的precheck检查
- 在执行器的开始,确认了触发器等关于这次操作的所有表,做最后的权限检查。