Golang的map底层实现
一、Map的底层数据结构
Golang的map数据类型底层使用的是哈希表实现,一个哈希表可以有多个哈希表节点,即bucket,一个bucket保存着map中的一个或者一组键值对。
hmap的数据结构:
map的实现实际上就是runtime包里的hmap:
// 定义在src/runtime/map.go中
type hmap struct{
count int // 当前保存的元素个数
...
B uint8 // 指示bucket数组的大小
...
buckets unsafe.Pointer // bucket数组的指针,bucket数组的大小为2^B
}
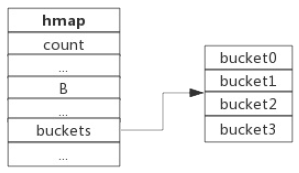
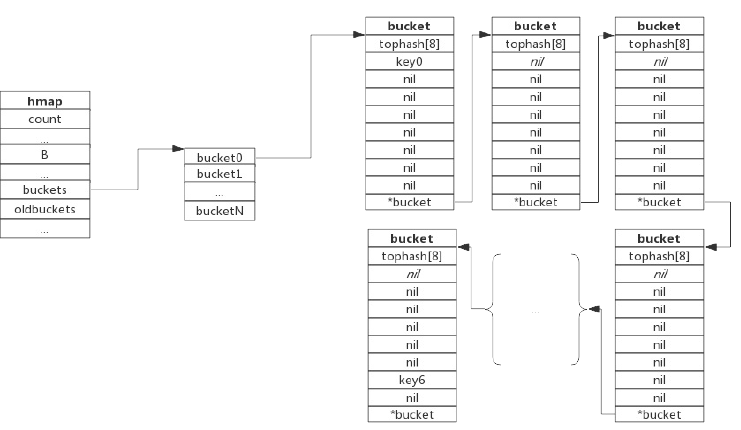
可以看到hmap中比较关键的参数:count就是当前保存的键值对个数;B是bucket数组的大小,buckets是一个unsafe.Pointer指针,指向多个bucket组成的一个数组,这个数组的大小是2的B次方。一个hmap大概长下图这样,下图是一个B值为2的hmap,可以看到buckets数组的长度是4:
bucket的数据结构
bucket一般被翻译成桶,就是所谓的哈希桶。元素存储到hmap中时,会进行哈希函数的运算,然后就会落在buckets数组中的某个具体的bucket上。bucket的数据结构体如下:
// 以下是简化版本,实际并不是这么显示定义的,而是通过指针运算访问的
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data //存储k-v数据,按照key/key/key/.../value/value/value...的格式存储
overflow *bmap //溢出bucket的地址
}
hmap中buckets数组中的每一个bucket实际上就是一个bmap对象。bmap对象的关键字段有三个:
- tophash是个8位的uint数组,存储的是哈希值的高八位,当哈希值计算出来后,低八位用于计算出数据存储在hmap的buckets数组的哪个位置,高八位则会存储在bucket中的tophash这个数组里,tophash的长度是8,即可以存8个高位哈希值,也就是说一个bucket能存8个key-value。
- data中存储具体的key-value数据,一个bucket中会存8个key-value,存储的方式是先存8key再存value,这样做的原因是为了节省字节对齐造成的空间浪费。
- overflow是一个指针指向的是另一个bucket,当出现哈希冲突时,会通过链表的方式新增一个bucket,然后把数据保存到新bucket中,overflow就是指向链表中下一个bucket的指针。
整体的结构如下:
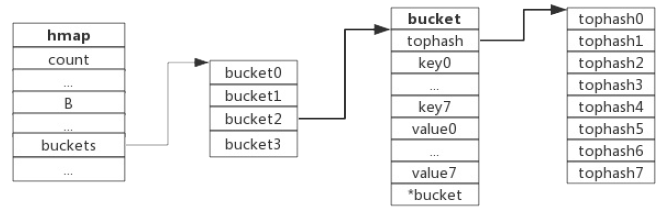
可以看到:tophash字段中能存8个高位哈希值,然后data中存储key-value,*bucket就是overflow,指向的是哈希冲突时创建的下一个bucket。
bmap的实际结构是这样的,只有一个tophash字段:
type bmap struct {
tophash [bucketCnt]uint8
}
然后在编译的时候会加料:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
原理上和上述描述的都是一样的。
二、哈希冲突
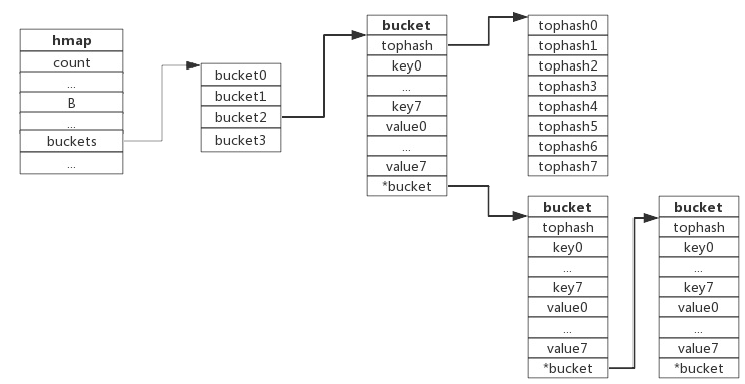
当有两个key经过哈希运算时低8位相同从而导致被分配到了同一个bucket上,这就说明出现了哈希冲突,而一个bucket可以存放8个key-value,所以会将高八位哈希值存在tophash字段上,然后把key-value存在data字段上。当8个位置都存满了,就会使用类似链表的方式把这个bucket链向一个新的bucket。overflow字段就是指向这个新bucket的字段(顾名思义,overflow就是溢出的意思)。
就像下图这样:
负载因子
负载因子用于衡量一个哈希表的冲突情况 ,计算公式是:
负载因子 = kv数量/bucket数量
所以,对于一个bucket数量为4,包含4个键值对的哈希表来说,哈希表的负载因子为1。
哈希表需要将负载因子控制在合适的大小,超过其阈值要进行rehash,重新哈希,键值对要重新组织。
哈希因子过小,说明空间利用率低,因为键值对数量远远小于bucket数量,空间占的太多又没存什么数据;哈希因子过大,说明哈希冲突严重,存取效率低,bucket都存满了,每次查找都要去遍历一个bucket的tophash列表才能找到数据,时间复杂度就不到O(1)了。
每个哈希表的实现对负载因子的容忍程度不同,比如redis实现中负载因子大于1时就会触发rehash,而Go会在负载因子到达6.5时才会rehash,Go的容忍性高的主要原因是Go的bucket可以存8个键值对,而redis的每个bucket只存一个。
渐进式扩容
当新元素要添加进map时,都会检查是否需要扩容。扩容触发的条件有两个:
-
负载因子:
当负载因子大于6.5时会触发扩容,即每个bucket中存储的键值对平均都达到了6.5个,已经逼近了8个的上限,空间占用率太高,存取效率太低。
-
overflow的数量达到了2的15次方,即哈希冲突导致了2^15个新bucket被链在了原bucket上。
负载因子过大会触发增量扩容,而overflow数量过多会触发等量扩容。这两种触发方式也对应着不同的场景。
增量扩容
增量扩容就是当负载因子过大时,就在hmap中新建一个buckets数组,新的buckets数组的大小会是旧的二倍然后将旧的buckets里存储的数据迁移到新buckets中。如下图:
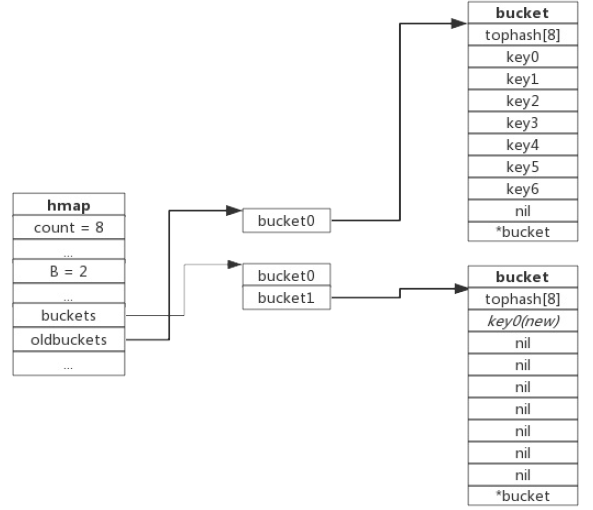
oldbuckets就是旧的数组,只有一个bucket,且这一个bucket中存了7个键值对,负载因子是7,大于6.5,于是触发扩容,扩容时新建一个buckets数组,且这个bucket数组中有两个bucket,即bucket个数是原来的两倍。此时新的数据插入这个map时,就会保存在心的buckets中,而不是oldbuckets。
当对map进行扩容时,考虑到如果map存储了数以亿计的key-value时,一次性搬迁会有很高的耗时,Go采用逐步搬迁的策略:每次访问map时都会触发一次搬迁,每次会搬迁2个键值对过去,等oldbuckets中的数据全部迁移完成后,就会删除oldbuckets。
等量扩容
等量扩容指的是buckets数目不变,重新做一遍类似增量扩容的动作,把松散的键值对重新排列一次,让bucket的使用效率更高,保证更快速的存取。等量扩容解决的是某些场景下导致的键值都集中在一小部分bucket中,overflow的bucket过多,但是负载因子又不高的情况,即第二种触发扩容的条件。他会把比较满的bucket中的键值对转移到另一些比较空的键值对中。
三、Map查找key的过程
- 根据key值算出哈希值;
- 取哈希值低8位与hmap.B取模后确定落在buckets数组中的哪一个bucket上;
- 取哈希值高8位在bucket的tophash中遍历查询;
- 如果tophash中有这个高位哈希值,则可以从data中找到key和value;
- 如果tophash中没有找到高位哈希值,则去overflow的bucket中查找;
- 如果当前处于搬迁过程,则优先从oldbuckets数组中查找;
- 如果查找不到,也不会返回空值,而是返回对应数据类型的0值(int就是0,string就是"")。
四、Map插入key的过程
- 根据key值算出哈希值;
- 取哈希值低位与hmap.B取模确定bucket位置;
- bucket中查找哈希值高八位是否存在,如果存在就获取key检查和想要插入的key是否相同,相同则直接更新值;
- 高八位哈希值存在,但是key却不同则是哈希冲突,需要新创建一个bucket,然后用overflow指向这个bucket,然后把新key存进overflow的bucket中;
- 如果高八位哈希值在tophash中不存在,则把高八位哈希值保存到tophash数组中,并将key-value插入到data。