Docker的底层原理——Namespace和Cgroups技术
一、容器技术
容器是一种沙盒技术,可以像一个集装箱一样,把你写的应用程序包起来,这样多个应用之间就会有各自的边界而不互相干扰,而这个容器也可以随意的搬来搬去。容器在外在表现上就像一个轻量级的虚拟机,它有自己的文件系统,自己的CPU和内存大小,自己的网络栈等等,多个容器运行在同一台宿主机上,就像每个容器各自从一台物理机上切了一块一样。但是容器并不像虚拟机一样采用了虚拟化技术,而是直接在操作系统上就可以隔离出多个容器。下面这张图就是容器和虚拟机的对比图:
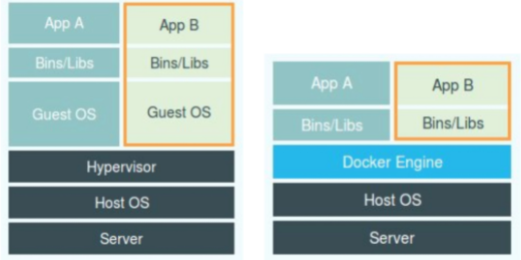
左侧就是虚拟机的实现原理,通过Hypervisor提供硬件虚拟化功能,模拟出一个操作系统的各种硬件状况,然后在这个虚拟的硬件上安装一个新的操作系统,也就是图上的Guest OS。
而右侧就是容器技术,可以看到容器是使用了Docker Engine替代了Hypervisor,并且不需要创建Guest OS,而是直接就构造出了多套文件目录。
那么容器技术到底是怎么实现的呢?
二、通过Namespace让进程"隔离"
Linux系统在使用clone()或者fork()函数创建一个进程时,可以给它指定很多参数,比如CLONE_NEWPID参数,就可以在进程创建起来后,让这个进程"看到"一个全新的进程空间:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
在这个进程空间中,它自己的PID为1,而且看不见物理机上的其他进程PID,这实际上是一个障眼法,因为这个进程在物理机上仍然有它真实的PID,比如100。
除了PID Namespace的参数之外,Linux还提供了Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文设置“障眼法”。比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络栈。
通过这些大量的Namespace技术,就可以让一个进程只能看到自己Namespace里限定的文件系统、网络资源等信息,让它以为自己是独立的。所以说容器,其实就是操作系统在启动进程时通过设置一些参数实现了隔离不相关资源后的一个特殊进程。
三、通过Cgroups给进程进行"约束"
然后,只通过Namespace技术只能让一个进程以为自己被隔离了,他还是能够和宿主机上的其他进程共享一些宿主机上的基础资源,比如CPU和内存。在Linux内核中,还是有很多资源是不能被Namespace化的,比如时间,如果一个进程使用settimeofday(2)系统调用修改了时间,那么整个宿主机的时间都会被修改。就是说我们在一个容器里,虽然看到的是这个容器是完全隔离的,但是其实是不能想做什么就做什么的,我们依然不能像在一台虚拟机中一样,就把它当作一个独立的机器。除了“隔离”,我们还要解决给容器设“限制”的问题。
Cgroups就是 Linux 内核中用来为进程设置资源限制的一个重要功能。Linux Cgroups的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
在Linux中,Cgroups给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。我们通过命令mount -t cgroup可以进行查看:
# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
可以看到输出了一系列的文件系统目录,里面有cpuset、cpu、memory这样字样的目录。这些都是我这台机器当前可以被Cgroups进行限制的资源种类。
所以如果我们要个一个进程设置限制,只需要修改这些Cgroups文件组中各个资源的文件内容即可。比如,当我们创建一个进程时,通过指定各个Namespace参数让它”隔离“,然后再在Cgroups控制组文件中把这个进程的PID填写到对应控制组的 tasks 文件中就可以了。
至此,我们已经完成了在创建一个进程时,让它实现隔离,并且对其可使用的资源进行限制。而这就是Docker容器技术核心的底层实现原理。