CPU的cache line和false sharding问题
一、CPU的多级缓存
随着计算机进入多核时代,CPU处理速度和内存之间的鸿沟越来越大,因此多核CPU都通过缓存行提高CPU和内存的交互效率。CPU 缓存(Cache Memory)是位于 CPU 与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内 CPU 即将访问的,当 CPU 调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
CPU根据型号不同缓存的数量也不同,一般会有三层以上的缓存,:
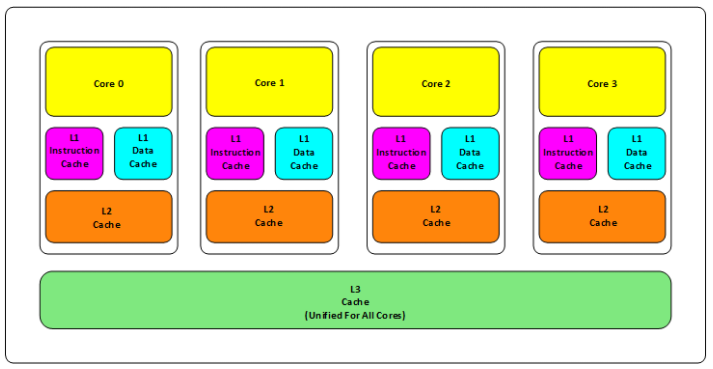
如上图,是一颗CPU的典型架构,一共有三级缓存
- L1 缓存:一般都是分成指令缓存,和数据缓存,分开放。
- L2 缓存:从 L2 缓存开始部分指令和数据,L1 和 L2 缓存都是在一个真实的核中的。
- L3 缓存:从 L3 开始,往往都是一颗CPU中所有核心共享的。
这三级缓存也是离CPU越远的速度越慢:
- L1的存取速度:4个CPU时钟周期
- L2的存取速度:11个CPU时钟周期
- L3的存取速度:39个CPU时钟周期
- 内存的存取速度:107个时钟周期
对于存储空间来说:
- L1一般64kb
- L2一般256kb
- L3有2M
每级缓存中存储的数据都是上层缓存的一个子集:比如 L1 就是 L2 的子集,L2 是 L3 的子集, L3 又是内存的一个子集。
缓存为什么要设置成三级?
主要基于如下考量:
- 缓存级数越多,多个缓存命中反而速度会下降。
- 由于核心独立缓存的设置,还要考虑多个核心访问同一块数据时的同步问题,明显缓存级数越多,同步过程越复杂。
二、Cache line
缓存系统中是以缓存行(cache line)为单位存储的,CPU 从内存中捞数据时都是一次性捞多个,而不是一次只捞一个字节,这样效率太低。而 CPU 每次从内存中加载到的数据的大小就是缓存行(Cache line)。主流的大小是64字节,就是16个32位的整型数据,即如果有一个 int32 类型的数组,那么在CPU加载数组的第一个元素时,会把数组的前16个元素全部加载到 L3 缓存中。但如果你用的是链表存储数据,链表中的并不是挨着的,也就不能用到CPU缓存所带来的性能提升。
因为cache line缓存行有固定值,所以L1、L2、L3都得是cache line的倍数。可以理解为CPU的多级缓存中就是一个又一个的cache line。
CPU加载内存数据的过程
- CPU从内存中会以cache line的长度获取数据,并根据 LRU 算法放进 L3 缓存中,当 L3 中的数据访问频繁,就会也被加到 L2,L1,依次类推。
- 如果CPU在计算的过程中另外想要拿到的数据刚好在 L1 中,就直接从 L1 拿;没有就从 L2 拿;再没有就去 L3 拿,再没有就去内存拿,这里是假设了同时需要被计算的数据往往在内存中都是连续存储的。
缓存的一致性
CPU的写操作分为两种:
- write back:写操作只写cache,然后再flush到内存。
- write through:写操作同时写cache和内存。
因为内存和cache的性能鸿沟,所以同时写的话太慢了,一般都会采用write back的方案。但是这样就会有这样一个场景,当多个线程操作的数据,刚好在同一个缓存行时,就需要通过协议来进行同步,大量同步反而会造成性能下降,甚至还不如没有缓存行,就出现了伪共享(False sharding)问题。
三、False sharding
MESI协议和RFO请求
多线程编程时,一个核想要访问另一个核的 L1 或 L2 级缓存上的数据时,该怎么办呢?容易想到的方法是让这个核直接跨核心去访问另一个核的数据,这种方法的缺点是速度不够快,跨核访问需要通过 Memory Controller (内存控制器,用于CPU核心间的数据交换)。典型的情况是第 2 个核经常访问第 1 个核的这条数据,那么每次都有跨核的消耗。更糟的是,有可能第 2 个核与第 1 个核就不在一个插槽内;况且 Memory Controller 的总线带宽是有限的,也扛不住这么多数据传输。
所以CPU 设计者们更偏向于另一种办法: 如果第 2 个核需要这份数据,就由第 1 个核直接把数据内容发过去,既然你要用这块缓存,我就把这块缓存全都发给你,免得你老是来找我要。
还有一个问题,在什么时候核心1要去另一个核心2中取数据呢?就是在核心2修改了自己缓存中的数据,导致它的缓存和内存不一致时,这时我们就说这个被修改的缓存行是脏缓存行。只有在核心2的缓存中的数据才是最新版本,那么当核心1要去改这个缓存行,就要从核心2中去拿这个缓存行的最新版本,而不能去内存中拿。那么核心1如何判断 核心 2 修改了那个自己需要的缓存行呢,就是通过MESI协议。
MESI协议
MESI协议通过M、E、S、I代表一颗核心中的某个缓存行的四种状态:
- M(Modified):修改,本地处理器已经修改了缓存行,即这个缓存行是脏行,和内存中不一致。
- E(Exclusive):专有,缓存行内容和内存中是一致的,但是这个缓存行只有当前处理器有加载,其他处理器都没有。
- S(Shared):共享,缓存行内容和内存中的一样,也有可能其他处理器也拥有这个缓存行。
- I(Invalid):无效,这个缓存行失效了,不能使用。
当核心进行数据处理时,核心中的缓存行会进行四种状态的转换:
- 一开始时,核心还没有加载数据到这个缓存行,此时处于 I 状态
- 本地读 (Local Read):当核心读取处于 I 状态的缓存行,而此时这个缓存行还是无效的,那就分为两种情况:
- 其他核心的缓存里也没有这行的数据,则此核心会从内存中加载数据到此缓存行中,同时更改它的状态为 E。
- 其他核心的缓存中有这行数据,则从内存中读到数据后,更改此缓存行的状态为 S。
- 本地写 (Local Write):当本地处理器写数据到这个缓存行,则缓存行的状态变为 M。
- 远程读 (Remote Read):如果核心1想要读取核心2的缓存行内容,则核心2需要将自己的缓存行数据通过 Memory Controller 发给核心1,核心1在收到这行数据后,就会把对应的缓存行状态设为 S。同时内存也要加载这行数据,即远程读的时候,要刷一下脏行到内存。
- 远程写 (Remote Write):远程写发生在远程读之后,因为只有读了才能写,当核心1对核心2执行了远程读操作后,核心1再向核心2发送一个RFO(Request For Owner)请求,意思是它要修改这份数据,其他的所有核心中这行数据所在的缓存行状态要改为 I,即其他核心都不能再动这行数据。
发送RFO消息的代价很高,因为它会将所有其他核心上持有这行数据的缓存行置为 I ,当其他核心要再次操作这行数据时,就要再发RFO消息,多核同时操作这行数据时,每一次都只有一颗核心可以操作,多线程并发形同虚设。
下图是一个False sharding的例子:
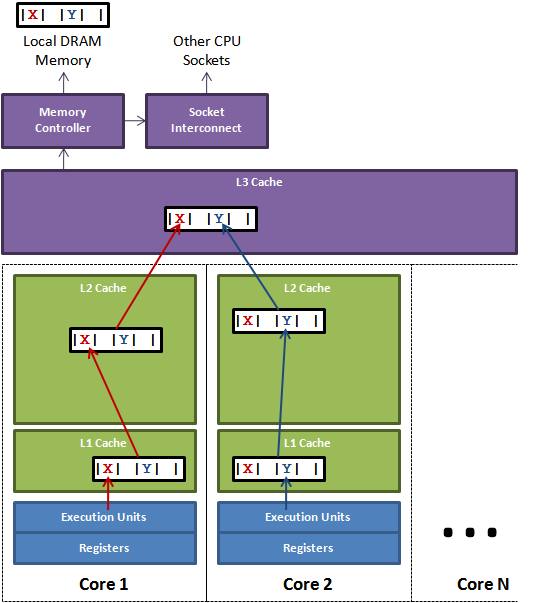
X和Y这两块数据,在同一个缓存行中,并且这个缓存行在 Core 1和 Core 2都有缓存,那么Core 1要操作X,Core 2要操作 Y,那么他们就要轮流发送RFO消息,轮流控制这个缓存行。而每一次的修改,都会使另一个核心的缓存行失效变为 I 状态。那么它就要从 L3 Cache中获取,而读 L3 的数据非常影响性能,更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。就因为这两个数据共享了一个缓存行,就造成了 L1 和 L2 缓存的几乎失效。而所有的竞争冲突都是来源于共享。
如何避免False sharding
既然False sharding的根本原因,就是缓存行共享。那么解决方式自然是不要共享,我们知道一个缓存行有64个字节,当我们用多线程操作数据时,尽量让这些数据不在一个缓存行中,比如我们可以通过填充缓存行的方式,把多线程操作的多个数据隔离开,让他们不要共享。
举个例子,比如我有一个线程 A,它要操作一个数组 1,还有一个线程B,要操作数组 2,那么我们就把数组 1和数组 2填充到两倍的 cache line 大小,则无论两个数组在内存中是如何排布的,CPU在取任何一个数组的任何一个元素,在加载到自己缓存的 cache line 时,这个cache line中都不可能拥有另一个数组中的元素,两个数组的元素永远都不可能在同一个 cache line 中,则不会有 False sharding 问题了。
实际开发中要不要关注False sharding
False sharding问题十分隐蔽,而且不同的机器缓存行大小也不一样,不同的语言不同的数据结构,不同的业务代码,占用的缓存空间也不一样,我们暂时也无法从系统层面上通过工具来探测伪共享事件。而且填充缓存行也会造成CPU缓存的浪费。
所以这个问题,如果是很底层的开发,十分要求性能,那么根据实际情况可以考虑优化这个问题。如果是上层开发,没那么极端的要求,在这个问题上浪费时间,我觉得就有些得不偿失了。