分布式锁的几种实现方式
分布式锁
单机锁
就是本地应用的互斥锁,或者读写锁,用来锁住某个资源,先获取锁才能操作资源,为了并发安全,多个线程操作同一个资源时不会出现意外的情况,保证同一个时刻只有一个线程可以操作这个资源。
分布式锁
就是同样是某个资源,但是会有分布式的应用同时访问,同样需要保证任意时刻只有一个应用能访问这个资源,就需要使用分布式锁。
简单理解,单机锁用于进程内的多个线程争抢同一个资源,分布式锁就是系统内多个进程争抢同一个资源。
比如电商网站的秒杀,特价之类的活动,高并发下会出现成千上万人抢购一个商品的场景。系统设计时会通过限流、异步、排队等方式优化,但整体的并发还是平时的数倍以上,参加活动的商品一般都是限量库存,分布式锁就是一个防止库存超卖,避免并发问题的解决方案。
分布式锁的一般特性
- 互斥性:一个应用获取了锁,那么另一个应用就不能获取。这是最基本的。
- 可重入性:一个线程获取了这个锁之后,在持有锁的时间,依然可以再次获取到这个锁,只需要计数加1,同时释放锁时如果是已经重入的锁,只需要给计数减一即可,不用删除,该程序依然保有这个锁。
- 锁超时:为了防止一个线程给资源加锁之后挂掉,导致不能释放锁,其他应用迟迟不能获取这个锁,就需要给锁设置超时时间,让他自动解锁。
- 高效:加锁、解锁的操作要高效,这里不能成为性能瓶颈。
- 高可用:分布式锁要多个副本,防止单点故障后,整个分布式锁就不能用。
- 支持阻塞和非阻塞式的使用:当一个锁被其他线程持有时,这个线程获取锁的操作会阻塞住,直到可以获取锁,这就是阻塞。非阻塞就是获取不到锁就立刻返回,需要定时获取,或者轮询的方式直到拿到锁,直到一定时间之后,可以抛出拿不到锁的异常。
- 公平锁和非公平锁:公平锁就是,每个想要获取锁的线程排队,等到锁释放了,就按照先后顺序依次获得锁。非公平锁就是每次锁释放都是所以线程抢夺锁,谁先抢到是谁的,这种就可能出现某个线程长时间都拿不到锁的情况。
MySQL实现分布式锁
如果项目中本来就用了MySQL,其实就可以利用MySQL做一个分布式锁。虽然很少会使用用这种方案,但是理论上也是可行的。
实现方式
方法1
创建一个表,作为分布式锁的表。每个需要被锁的资源都有一个约定好的名字,加锁就是在表中插入一行,资源名字段填写特定的资源,解锁就是删去这一行。
表结构设计
- resource_name:资源名,这个字段要设唯一索引
- thread_info:当前占有锁的线程名
- count:被锁的次数,为了实现可重入
- create_time:首次加锁的时间
- update_time:最近一次加锁的时间
有个这个表,当我们想给某个资源加锁时,就先在表中创建一条记录,如果发现该资源已经有记录了,就说明已经被别的线程锁住了,就要等待锁释放。释放锁就是从表中删掉这条记录,如果count不是0,那就说明有锁的重入,只需要给count减1即可。
方法2
如果锁住的资源刚好是数据库表中的某一行记录,那就可以不新建表了,直接修改表结构,把方法1中的字段直接加在这个表上。resource_name就改为lock即可
获取锁就是给这行记录的lock字段置为true,释放锁就是将lock置为false,或者将count值减1。
加锁的伪代码
select * from lock where resource_name=="XXX"; // 查询是否资源加了锁
if 加了锁{
检查是不是自己加的,如果是自己加的那可以重入,count + 1,并且返回true,加锁成功
if thread_info == 自己{
update count++ where resource_name = "XXXX
return true
}else{
// 不是自己加的锁,那就不能得到锁了
return false
}
}
// 没加锁的话,就可以加上锁了
insert into lock (resource_name, thread_info), ("XXX", "线程名")
return true
需要注意的点就是并发时业务代码的Check-lock-Check问题(Golang的单例模式中有描述这种并发问题),防止出现并发时被覆盖加锁的问题。
还有要做超时处理,当一直返回false时需要返回错误。可以写一个定时任务循环遍历锁,判断create_time和update_time距离现在的时间(thread_info要一样),太长时间没更新这个锁就要删除。或者也可以用懒加载的方式,每个获取锁的程序在检查是否可以获取锁时,顺便检查create_time和update_time,超时了直接删掉,并且自己直接加锁。
MySQL分布式锁的优缺点
优点:
- 项目中用到了MySQL就可以使用,不用增加中间件
缺点:
- 加锁解锁的代码需要自己写;
- 磁盘型数据库,性能较差;
- 功能太简单,公平锁,阻塞非阻塞都不能用;
- 不支持高可用,加锁解锁都只能操作主库,从从库读锁也因为主从延迟的问题导致不可信。
总结
MySQL的分布式锁缺点太大,导致几乎不能用,这里仅作为帮助理解分布式锁的方案。
Zookeeper实现分布式锁
zookeeper是一个以Paxos共识算法为基础的分布式应用协调服务。就是个分布式强一致的数据库。Zookeeper以Znode为存储单元的分布式数据存储结构:
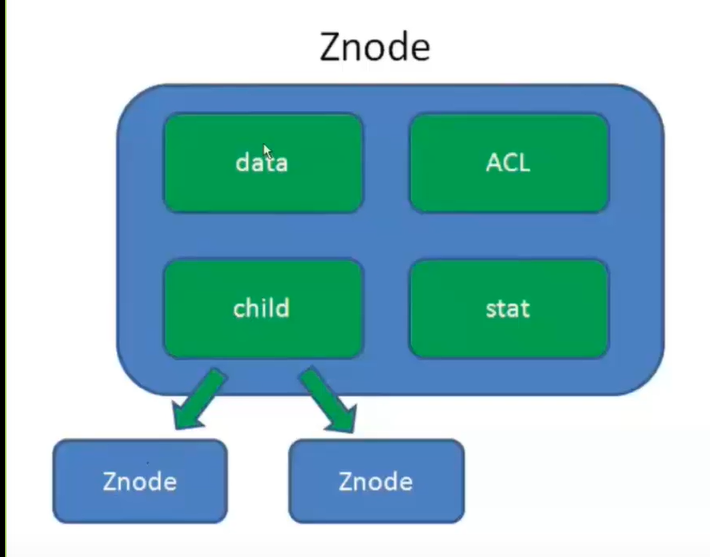
- data:znode存储的数据信息
- ACL:记录znode的访问权限
- stat:包含znode的各种元数据
- child:子Znode节点
可以看出zookeeper就是一个树形的结构,类似文件系统的目录。
实现方式
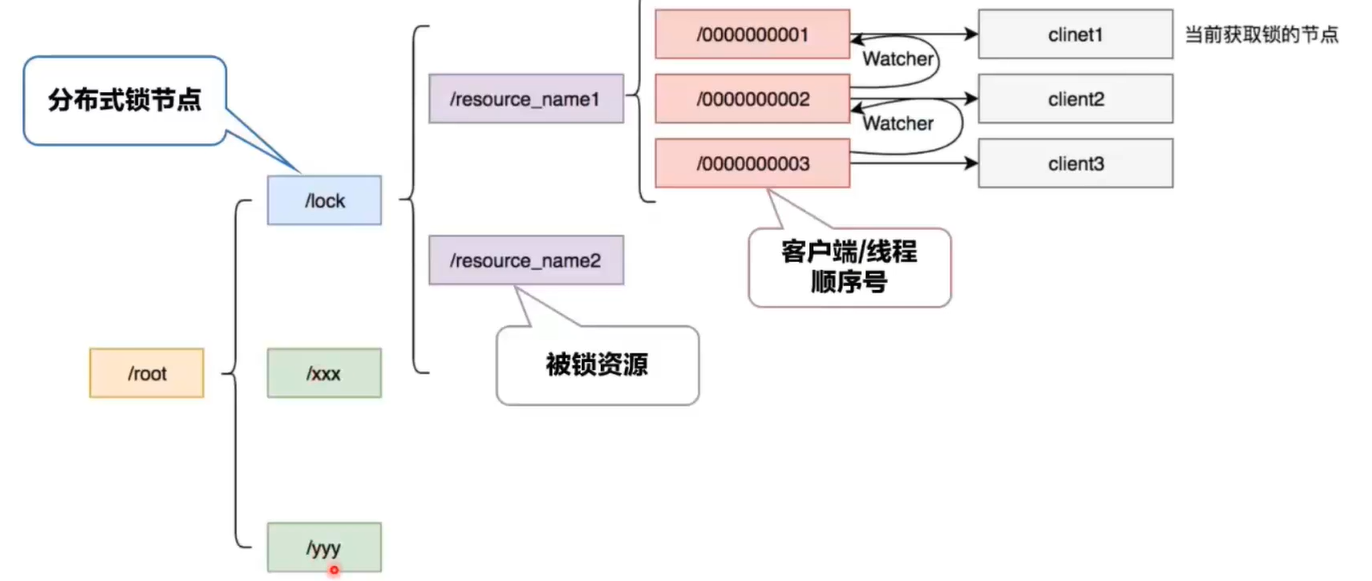
首先新建一个lock节点,lock节点的每个子节点都是被锁资源的名称。
资源节点下可以建立多个临时有序节点,临时有序节点是zookeeper的数据结构,按建立顺序天然有序。每个客户端想要获取锁都是给资源节点建立子的临时有序节点,通过判断自己创建出的临时有序节点是不是1号,得知自己有没有获取到锁。
如果临时有序节点不是1,那么zookeeper中会向他的上一个临时有序节点建立一个watcher,当1号有序节点被删除,每个节点会自动向上提升,并且由于注册了watcher,当节点成为1时,客户端也会收到通知,所以zookeeper天生是公平锁。
优缺点
优点
- 对于锁超时有现成的处理方法:建立的是临时有序节点,到时间会自动删除的
- 由于临时有序节点的存在所以是天然的公平锁
- Zookeeper是分布式协调服务,所以是天然高可用
缺点
- 如果项目中没用到Zookeeper,增加一个Zookeeper仅用于分布式锁的话开销有点大
- 性能上不比MySQL强多少,强一致性的性能都好不了
Etcd实现分布式锁
Etcd是一个分布式键值对数据库,使用raft共识算法保证强一致性,可以看做是paxos的简化版。
Etcd的特性:
- lease租约机制,每个键值对都有一个租约,相当于过期时间,到期自动删除
- revision版本号机制:每个key都是自己的版本号,并且被修改过的话,key版本号会增加,并且旧的key也不会删除,而是保存,直到执行了数据压缩
- prefix前缀机制:多个key都可以有相同的前缀,并且Etcd还能根据前缀查询
- watch机制:监听机制,可以watch某个固定的key,也可以watch某个前缀的所有key,当key变化时会收到通知
实现原理
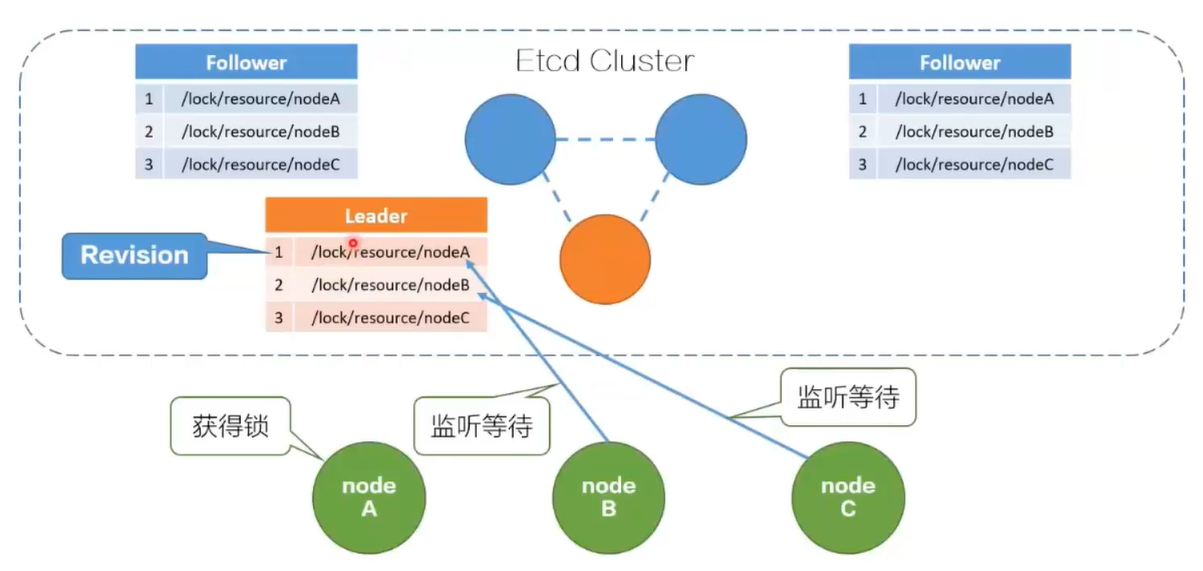
每个想拿锁的线程可以以资源名作为前缀创建一个key,可以获得一个版本号,如果版本号是最小的,那就代表持有锁了。
如果版本号不是最小的,就说明锁被其他线程持有了,那么这个线程就会watch这个资源前缀的前一个版本号,当资源最小的版本被删除时,他会收到通知,同时再判断自己的版本号是不是最小的。
客户端可以创建一个定时任务,进行定时续约,防止锁自己的租约超时被删掉。
并且Etcd的v3接口原生就实现了分布式锁,可以直接使用。
优缺点
优点
- v3接口提供了现成的分布式锁实现,不用我们自己实现了
- 版本号的存在导致天然是公平锁
- Etcd也是分布式强一致数据库,所以天生高可用
缺点
- 和ZK一样,项目没用到强加开销大,不过Etcd稍微比ZK简单点
- 同样是强一致数据库,所以性能也不大行
Chubby实现分布式锁
Chubby是闭源的,是google版本的Zookeeper。它是一个专门的分布式锁服务,而Zookeeper定位是一个分布式协调服务。
Chubby在分布式锁的使用上比Zookeeper优秀的地方是:当超时时间快到了时,不会立刻释放锁,而是访问一下客户端,防止客户端不是因为挂了才不释放锁,而是真的处理业务时间过长,这种情况下可以等一会,等客户端来解锁,防止客户端解锁时发现锁已经是别人的了。
由于闭源用的人不多,总体上和Zookeeper差不多,所以就不细讲了。重点还是看Redis。
Redis实现分布式锁
这是使用最多的分布式锁实现方案。
简单实现
只需要在redis中设置一个key就可以了:
set resource_name value ex 5 nx // nx标识如果key不存在就创建,已存在的话就创建失败
就创建一个资源名的键即可,指定超时时间,nx表示不能重复创建,其他线程创建同名key时会报错。
需要注意的是Redis2.8之前由于不能设置键时指定ex,需要用lua脚本保证set key和expire两个命令的原子性。
数据结构选字符串就可以,或者如果想存更多信息的话也可以用hash表。
简单实现的问题:
-
不及时续约导致的问题:
-
超时lock被删:如果线程A获取了锁,然后超过了key的过期时间,导致key被删除,而线程A还没处理完,那么此时线程B就可以重新获得锁,然后操作资源,此时就有并发安全性。
-
误删其他线程占用的lock:当A线程处理完了,他还要释放锁,这是锁是B占有的,就会导致A把B的锁给误释放了,那么其他线程又可以在b没释放锁时拿到锁。
-
解决方式:
-
超时lock被删:
-
创建锁之后要起一个线程,如果没处理完,这个线程要去给key续约,可以通过执行任务的线程给续约线程发信号的方式通知续约线程,续约线程定时进行续约,收到信号就可以退出不再续约了。
-
尽量把比较耗时的操作不要放到加锁的方法内,锁内的方法要尽量控制时长。
-
摸不清楚耗时时间可以尽量设置大点,正常情况下耗时任务执行完了就会解锁,设置大点主要时为了防止异常情况下执行过长。
-
-
解决误删问题:
-
每个线程删锁时,要判断是不是自己加的,可以在value中加上自己的线程名字,如果不是自己加的锁,就不要删。
-
这里由于代码往往都不是原子的,可以使用lua脚本,先查询再删除的逻辑,保证原子性,防止小概率情况下的误删。
-
高级版实现
- 阻塞加锁
- 阻塞超时加锁
- 非阻塞异步的加锁,得到锁时唤醒回调
- 重入等高级特性可以通过lua脚本实现
只要通过代码实现即可,不多做赘述。
Redis分布式锁的优缺点
优点:
- Redis这个中间件在大多数项目中较常见,一般不需要增加其他中间件
- Redis的分布式锁很容易取得可靠性和性能的平衡
缺点:
- 可靠性不像Etcd、Zookeeper那么高,因为redis宕机会丢数据,如果是AOF持久化那最多就丢1s的数据
RedLock实现的分布式锁
Redis集群实现分布式锁的问题:
- Redis主从不是强一致性的,所以可能会有数据不一致的问题,读写分离的情况下,从库如果数据和主库不同,那么就会导致加锁解锁判断出现问题。
- Redis的常用的持久化,RDB,或者是1s同步的AOF都会丢数据,如果加锁后Redis宕机了,就会导致多个线程同时获取锁,出现并发安全问题。
RedLock就是为了解决以上问题,实现方式是:
- 建立多套(奇数)Redis集群,或者单机,总之是多套Redis系统
- 依次对所有Redis集群加锁
- 只要保证大多数redis集群都加锁成功了,就算是成功
- 如果不是大多数redis集群都加锁成功了,就要想其他成功的redis集群回滚,请求释放锁(在这一步方式少部分成功的redis集群宕机导致数据丢失)
RedLock其实是用概率的方式大大减少redis宕机导致锁失效的概率,多套redis同时在加锁之后宕机的概率几乎为0。
但是缺点也很明显:多套Redis(集群或者单点),大多数系统都接受不了。
工程实践
分布式系统设计是实现复杂性和收益的平衡,考虑到集群环境下的一致性问题,也要避免过度设计。在实际业务中,一般使用基于单点的 Redis 实现分布式锁就可以,顶多搞个Redis集群,或者哨兵模式保证Redis的高可用,如果出现数据不一致的情况,通过人工手段去回补即可。当然实际上还是根据业务的要求去选择好,对数据安全性要求高的场合,还是使用强一致性的分布式存储,或者用Chubby更合适。